

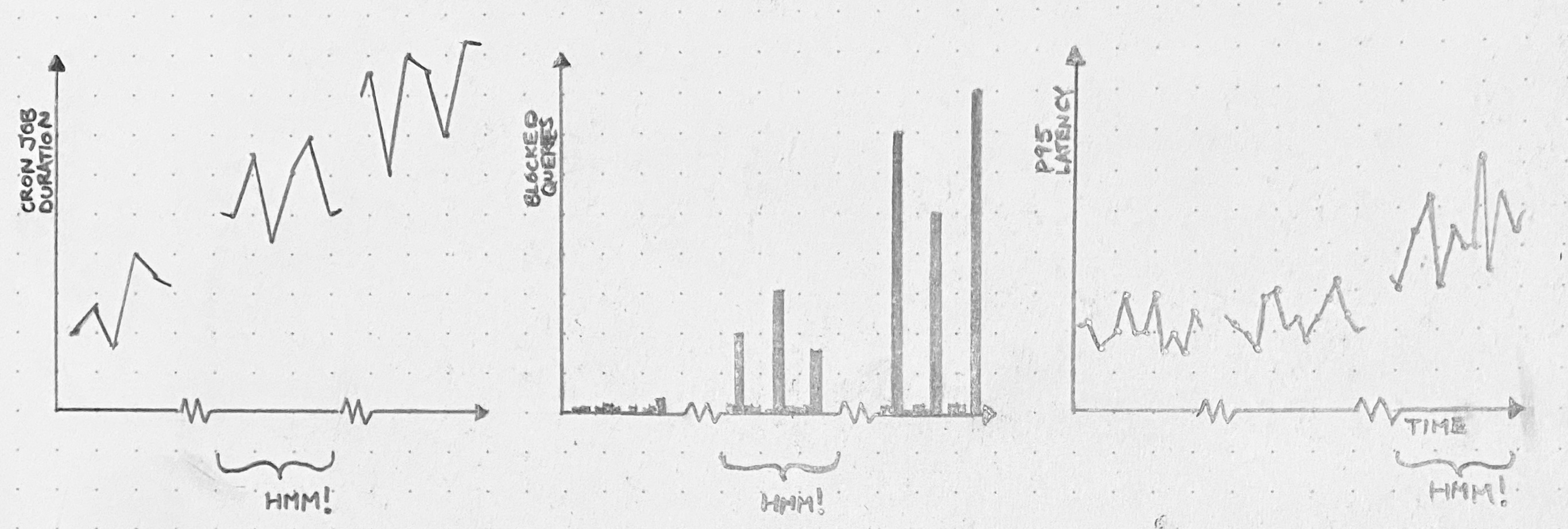
A bug in our deployment system causes O(N²) latency with respect to the number of deploys that have been performed. At first, it’s too minuscule to notice. But the average deploy latency grows over time. Eventually, deploys start randomly timing out. The deploy pipeline grinds to a halt, and it becomes an emergency.
Or maybe, if we think critically about the deploy latency time series soon enough, it might be obvious well in advance that something’s getting worse. We can fix this problem before it becomes a crisis. But in order to see it, we have to look. And we have to give ourselves time to go down the rabbit hole.
An API server has an edge case that leads to unconstrained memory usage. At first, this edge case only gets hit occasionally, and the API server’s memory usage stays well below capacity. But, as usage patterns evolve, we start to hit this bug more frequently, with larger and larger allocations of memory. For a while, we’re still below the OOMkill threshold. Once we start hitting that threshold, things get ugly. If we still continue to ignore it, then eventually, things will get so ugly that we’ll have to drop what we’re doing and fix this bug.
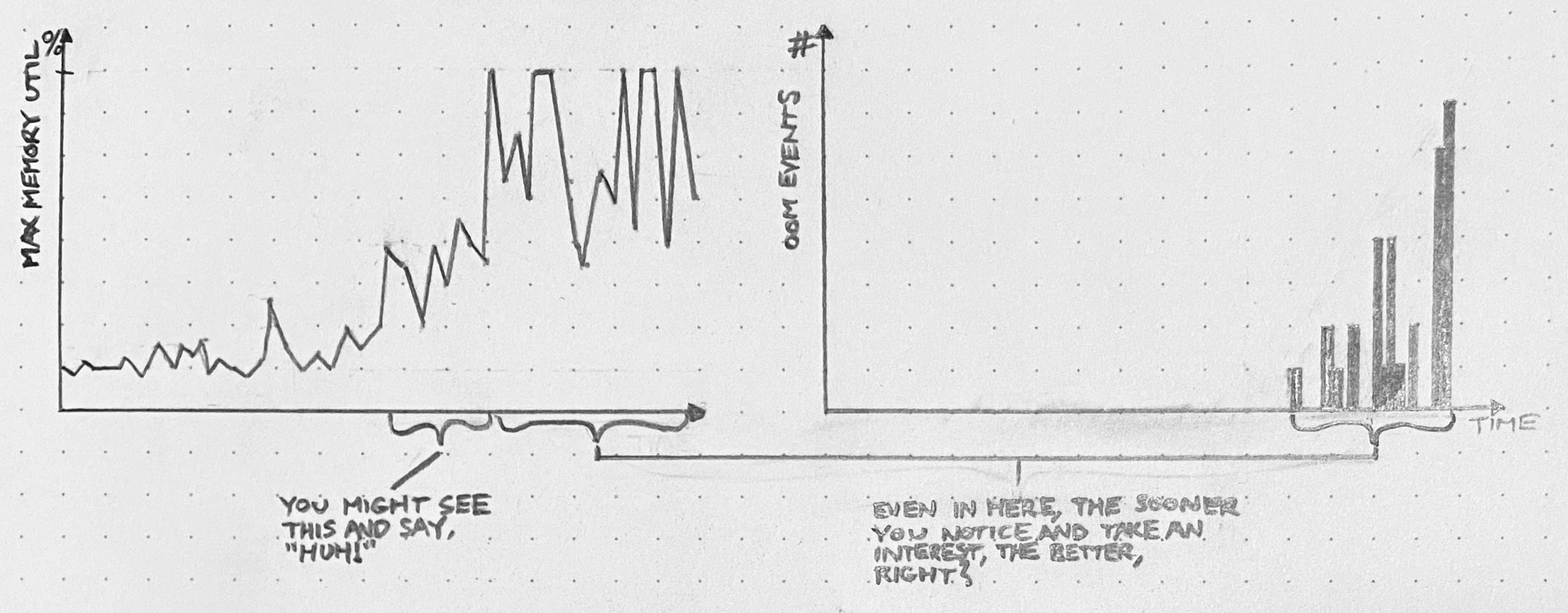
We had opportunities to see this coming. Depending on our willingness to dig in and investigate surprising phenomena, we could have discovered this problem when the OOMkills started, or even before they started – when these blips were just spikes on a memory graph.
A cron job runs every 30 minutes, and while it runs, it holds a database lock. When it’s first deployed, the cron job doesn’t have much to do, so it runs fast, and no one suffers. Over months, though, the cron job grows sluggish. It just has more work to do. Query pileups start to occur every 30 minutes. We start seeing significant impact on the latency of our application. And, one day, there’s an outage.
We’ll wish we’d dug in back when it was just a slow cron job. Or even when it was just query spikes.
You can prevent many things from turning into fires, but you need space. Space to be curious, to investigate, to explain your findings to yourself and others.
Suppose you spent a week looking for trouble like this, and you only happened to find 1 issue out of these 3. That’s still great, right? Compared to the cost of letting it become a disruption later?
When a system fails, it’s silly to blame practitioners for not seeing the signs. But that doesn’t mean we shouldn’t put in a serious effort to see the signs. If you give yourself space to follow the Huh!, you get opportunities to fix problems before they get worse.
