
Ever since the late 2000s, I’ve been implementing “alert review” processes on ops teams. As a team, we go through all the alerts we’ve received in the last week, and identify those that are bad.
But what makes an alert bad? How do we distinguish the good ones from the bad?
I use a simple framework wherein a good alert has the following properties:
- Actionable: Indicates a problem for which the recipient is well placed to take immediate corrective action.
- Investigable: (yes, I made this word up) Indicates a problem whose solution is not yet known by the organization.
These properties can be present or absent independently, so this framework identifies four types of alerts:
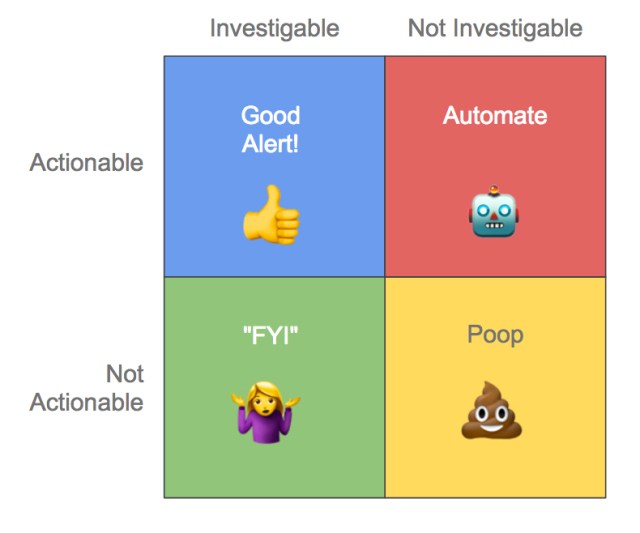
Actionability
Actionability has been widely touted as a necessary condition for good alerts, and for good reason. Why send an alert about something you can’t fix? Just to make the recipient anxious?
Referring to my definition of an actionable alert:
Indicates a problem for which the recipient is well placed to take immediate corrective action.
we can see three main ways in which non-actionability shows up:
- Someone is well placed to take immediate corrective action, but not the recipient. For example, an alert that indicates a problem with the Maple Syrup service instead pages the Butter team, which can’t do anything about it. In cases like these, the fix is often simple: change the alert’s recipient. Sometimes, though, you’ll first have to refactor your config to let it distinguish between Maple Syrup problems and Butter problems.
- There is an action to take, but it can’t be taken immediately. For example, Apache needs to be restarted, but the recipient of the alert isn’t sure whether this will cause an outage. This type of non-actionable alert often calls for either improved documentation (e.g. a “runbook” indicating steps to perform). Another example might be a disk space alert that has been slowly climbing for a while and just crossed a threshold: action can’t be taken immediately, because the team needs to agree upon an action to take.
- There is no action to take. For example, “CPU utilization” or “Packet loss.” These are your classic FYI alerts. Instead of alerting, these things should appear on a dashboard for use in troubleshooting when a problem is already known to exist.
Investigability
An alert is non-investigable if its implications are obvious at first glance. Here are the two most common types of non-investigable alerts:
- “Chief O’Brien” alerts. If you look at your phone and instantly know the commands you have to run to fix it, that’s a “Chief O’Brien” alert. There’s no need to bother a human to fix the issue; the response should be automated.
- Redundant alerts. Sometimes you get an alert for increased error rates from one of your services, and by the time you get up and get to your laptop, you’ve gotten 8 more similar alerts. The first one might well have been a perfectly good alert, but the other 8 are likely non-investigable. Whatever you learn in investigating the first one will apply to the rest in exactly the same way. The correct response to alerts like these is to use dependencies or grouping.
What to do with this framework
Like I said, I like to have my team go through all the alerts they’ve received in the last week and discuss them. Imagine a spreadsheet where each alert is a row and there are columns labeled Actionable? and Investigable?
Actually, don’t bother. I imagined one for you:

This actionability/investigability framework helps the team identify bad alerts and agree on the precise nature of their badness. And as a bonus, the data in these spreadsheets can shine a light on trends in alert quality over time.
I’ve had a lot of success with this framework throughout the years, and I’d like to hear how it works for others. Let me know if you try it out, or if you have a different model for addressing the same sorts of questions!

Pingback: Monitoring & Alert Test Strategy – Rafaela Azevedo
Pingback: SRE Weekly Issue #353 – SRE WEEKLY
Pingback: SRE Weekly Issue #353 – FDE