People make mistakes, and that’s fine.
We’ve come a long way in recognizing that humans are integral to our systems, and that human error is an unavoidable reality in these systems. There’s a lot of talk these days about the necessity of blameless postmortems (for example, this talk from Devops Days Brisbane and this blog post by Etsy’s Daniel Schauenberg), and I think that’s great.
The discussion around blamelessness usually focuses on the need to recognize human interaction as a part of a complex system, rather than external force. Like any system component, an operator is constrained to manipulate and examine the system in certain predefined ways. The gaps between the system’s access points inevitably leave blind spots. When you think about failures this way, it’s easier to move past human errors to a more productive analysis of those blind spots.
That’s all well and good, but I want to give a mathematical justification for blamelessness in postmortems. It follows directly from one of the fundamental theorems of probability.
Bayes’ Theorem
Some time in the mid 1700s, the British statistician and minister Thomas Bayes came up with a very useful tool. So useful, in fact, that Sir Harold Jeffreys said Bayes Theorem “is to the theory of probability what Pythagoras’s theorem is to geometry.”
Bayes’ Theorem lets us perform calculations on what are called conditional probabilities. A conditional probability is the probability of some event (we’ll call it E) given that another event (which we’ll call D) has occurred. Such a conditional probability would be written
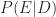
The “pipe” character between ‘E’ and ‘D’ is pronounced “given that.”
For example, let’s suppose that there’s a 10% probability of a traffic jam on your drive to work. We would write that as
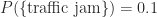
That’s just a regular old probability. But suppose we also know that, when there’s an accident on the highway, the probability of a traffic jam quadruples up to 40%. We would write that number, the probability of a traffic jam given that there’s been an accident, using the conditional probability notation:

Bayes’ Theorem lets us use conditional probabilities like these to calculate other conditional probabilities. It goes like this:

In our traffic example, we can use Bayes’ Theorem to calculate the probability that there’s been an accident given that there’s a traffic jam. Informally, you could call this the percentage of traffic jams for which car accidents are responsible. Assuming we know that the probability of a car accident on any given morning is 1 in 5, or 0.2, we can just plug the events in which we’re interested into Bayes’ Theorem:



Mistakes
Bayes’ Theorem can give us insight into the usefulness of assigning blame for engineering decisions that go awry. If you take away all the empathy- and complexity-based arguments for blameless postmortems, you still have a pretty solid reason to look past human error to find the root cause of a problem.
Engineers spend their days making a series of decisions, most of which are right but some of which are wrong. We can gauge the effectiveness of an engineer by the number N of decisions she makes in a given day and the probability P(M) that any given one of those decisions is a mistake.
Suppose we have a two-person engineering team — Eleanor and Liz — who work according to these parameters:
- Eleanor: Makes 120 decisions per day. Each decision has a 1-in-20 chance of being a mistake.
- Liz: Makes 30 decisions per day. Each decision has a 1-in-6 chance of being a mistake.
Eleanor is a better engineer both in terms of the quality and the quantity of her work. If one of these engineers needs to shape up, it’s clearly Liz. Without Eleanor, 4/5 of the product wouldn’t exist.
But if the manager of this team is in the habit of punishing engineers when their mistakes cause a visible problem (for example, by doing blameful postmortems), we’ll get a very different idea of the team’s distribution of skill. We can use Bayes’ Theorem to see this.
The system that Eleanor and Liz have built is running constantly, and let’s assume that it’s exercising all pieces of its functionality equally. That is, at any time, the system is equally likely to be executing any given behavior that’s been designed into it. (Sure, most systems strongly favor certain execution paths over others, but bear with me.)
Well, 120 out of 150 of the system’s design decisions were made by Eleanor, so there’s an 80% chance that the system is exercising Eleanor’s functionality. The other 20% of the time, it’s exercising Liz’s. So if a bug crops up, what’s the probability that Eleanor designed the buggy component? Let’s define event A as “Eleanor made the decision” and event B as “The decision is wrong”. Bayes’ theorem tells us that
which, in the context of our example, lets us calculate the probability P(A|B) that Eleanor made a particular decision given that the decision was wrong (i.e. contains a bug). We already know two of the quantities in this formula:
- P(B|A) reads as “the probability that a particular decision is wrong given that Eleanor made that decision.” Referring to Eleanor’s engineering skills above, we know that this probability is 1 in 20.
- P(A) is the probability that Eleanor made a particular decision in the system design. Since Eleanor makes 120 decisions a day and Liz only makes 30, P(A) is 120/150, or 4 in 5.
The last unknown variable in the formula is P(B): the probability that a given design decision is wrong. But we can calculate this too; I’ll let you figure out how. The answer is 11 in 150.
Now that we have all the numbers, let’s plug them in to our formula:
![P(A|B) = \frac{[1/20] \cdot [4/5]}{[11/150]}](https://s0.wp.com/latex.php?latex=P%28A%7CB%29+%3D+%5Cfrac%7B%5B1%2F20%5D+%5Ccdot+%5B4%2F5%5D%7D%7B%5B11%2F150%5D%7D+&bg=ffffff&fg=202020&s=0&c=20201002)

In other words, Eleanor’s decisions are responsible for 54.5% of the mistakes in the system design. Remember, this is despite the fact that Eleanor is clearly the better engineer! She’s both faster and more thorough than Liz.
So think about how backwards it would be to go chastising Eleanor for every bug of hers that got found. Blameful postmortems don’t even make sense from a purely probabilistic angle.
But but but…
Could Eleanor be a better engineer by making fewer mistakes? Of course. The point here is that she’s already objectively better at engineering than Liz, yet she ends up being responsible for more bugs than Liz.
Isn’t this a grotesquely oversimplified model of how engineering works? Of course. But there’s nothing to stop us from generalizing it to account for things like the interactions between design decisions, variations in the severity of mistakes, and so on. The basic idea would hold up.
Couldn’t Eleanor make even fewer mistakes if she slowed down? Probably. That’s a tradeoff that Eleanor and her manager could discuss. But the potential benefit isn’t so cut-and-dry. If Eleanor slowed down to 60 decisions per day with a mistake rate of 1:40, then
- fewer features (40% fewer!) would be making it out the door, and
- a higher proportion of the design decisions would now be made by bug-prone Liz, such that the proportion of decisions that are bad would only be reduced very slightly — from 7.33% to 7.22%
So if, for some crazy reason, you’re still stopping your postmortems at “Eleanor made a mistake,” stop it. You could be punishing engineers for being more effective.


