A couple weeks ago, my wife & I went to Basilica Block Party, a local music festival. It was a good time, and OH MANS you have to see Fitz & The Tantrums live. Their sax player is a hero unit.
Anyhoo, we walked over to the porta-potties between sets. The lines were about 8–10 people long. And my spouse suggested an intriguing strategy for minimizing her wait time. I will call this strategy The Strategy:
The Strategy: All else being equal, get in the line with the most men.
The reasoning behind The Strategy is obvious: women take longer to pee than men, so if 2 queues are the same length, then the faster-moving queue should be the one with fewer women. It’s intuitive, but due to my current obsession with queueing theory, I became intensely interested in the strategy’s implications. In particular, I started to wonder things like:
- How much can you expect to shave off your wait time by following The Strategy?
- How does the effectiveness of The Strategy vary with its popularity? Little’s Law tells us that the overall average wait time won’t be affected, but is The Strategy still effective if 10% of the crowd is using it? 25%? 90%?
And then I thought to myself “I could answer these questions through the magic of computation!”
qsim
Lately I’ve been seeing queueing systems everywhere I go, so I figured it’d be worthwhile to write a generic queueing system simulator to satisfy my curiosity. That’s what I did. It’s called qsim.
To quote the README,
A queueing system in
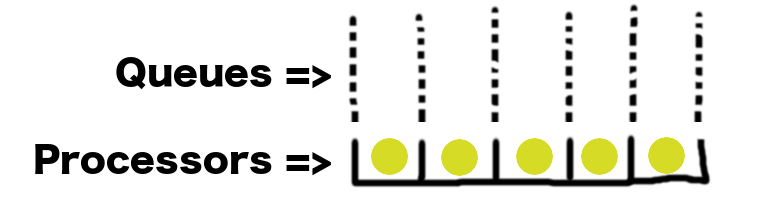
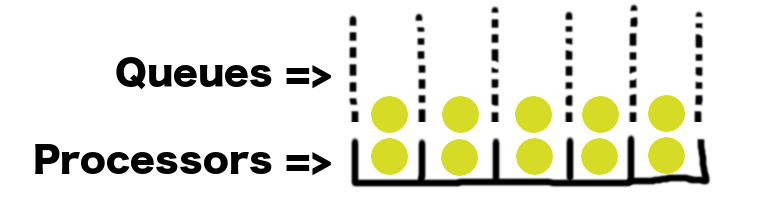
qsimprocesses arbitrary jobs and is composed of 5 pieces:
- The arrival process controls how often jobs enter the system.
- The arrival behavior defines what happens when a new job arrives. When the arrival process generates a new job, the arrival behavior either sends it straight to a processor or appends it to a queue.
- Queues are simply holding pens for jobs. A system may have many queues associated with different processors.
- A queueing discipline defines the relationship between queues and processors. It’s responsible for choosing the next job to process and assigning that job to a processor.
- Processors are the entities that remove jobs from the system. A processor may take differing amounts of time to process different jobs. Once a job has been processed, it leaves the queueing system.
qsim provides a framework for implementing these building blocks and putting them together, and it also provides hooks that can be used to gather data about a simulation as it runs. I’m really looking forward to using qsim to gain insight into all sorts of different systems.
For now: porta-potties.
The porta-potty simulation
You’ll recall The Strategy:
The Strategy: All else being equal, get in the line with the most men.
To determine the effectiveness of The Strategy, I implemented PortaPottySystem using qsim. Here are some of the assumptions I made:
- People arrive very frequently, but if all the queues are too long (8 people) they leave.
- There are 15 porta-potties, each with its own queue. Once a person enters a queue, they stay in that queue until the corresponding porta-potty is vacant.
- Shockingly, I couldn’t find any reliable data on the empirical distribution of pee times by sex, so I chose a normal distribution with a mean of 40 seconds for men and 60 seconds for women.
- Most people just pick a random queue to join (as long as it’s no longer than the shortest queue), but some people use The Strategy of getting into the queue with the highest man:woman ratio (again, as long as it’s no longer than the shortest queue).
- Nobody’s going number 2 because that’s gross.
- Everyone is either a man or a woman. I know all about gender being a spectrum, and if you want to submit a pull request that smashes the gender binary, please do.
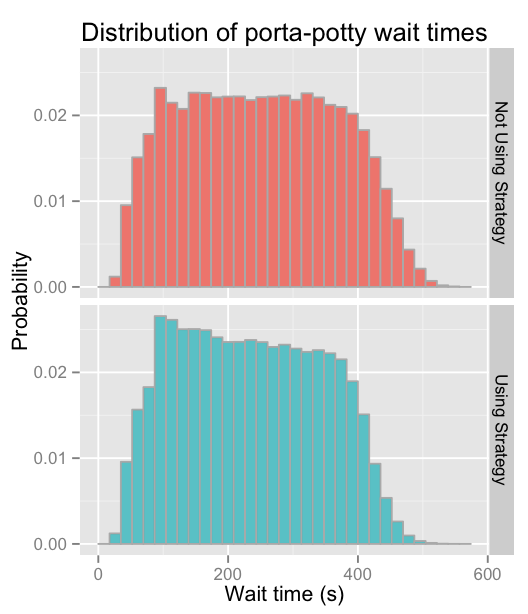
The first question I wanted to answer was: how does using The Strategy affect your wait time?
To answer this question, I ran a simulation where the probability of a given person deciding to use The Strategy is 1%. The other 99% of people simply join one of the shortest queues without regard to its man:woman ratio. I ran 20 simulations, each for the equivalent of 2 weeks, and came up with these wait time distributions:
More of a box-plot person? I hear ya:
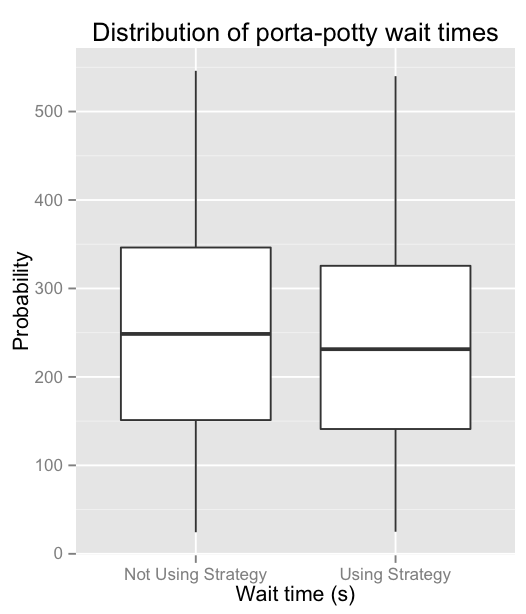
The Strategy is definitely not a huge win here. On average, your wait time will be reduced by about 10–15 seconds (4–6%) if you use The Strategy. Still, it’s not nothing, right?
Now how does the benefit of using The Strategy vary with its popularity? This is actually really interesting. I never would have guessed it. But the data shows that you should always use The Strategy, even if everybody else is using it too.
Here I’ve charted average wait times against the proportion of people using the strategy. Colors are more prominent where the data set in question is large (and therefore heavily influences the overall average):
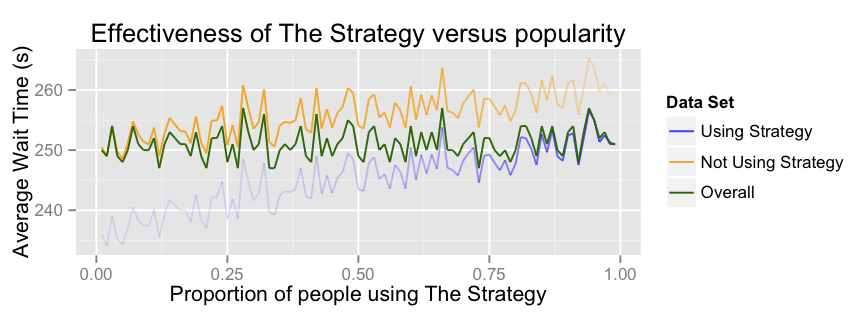
You’ll notice that the overall average (dark green) does not vary with Strategy popularity. This is good news, because otherwise we’d be violating Little’s Law, which would probably just mean our simulation was broken.
The interesting thing here is that the benefit of using The Strategy decreases pretty much linearly as its popularity increases, but at the same time there accrues a disadvantage to not using it. If everybody else in the system is using The Strategy, and you come along and decide not to, you can still expect to wait 10 seconds longer than everybody else. Therefore using The Strategy is unequivocally better than not using The Strategy.
Unless of course you don’t really care about those 10 seconds, in which case you should do whatever you want.