
In SaaS, when we’re hiring engineers, we usually imagine that their time will mostly be spent building things. So we never forget to interview for skills at building stuff. Sometimes we ask candidates to write code on the fly. Other times we ask them to whiteboard out a sensible architecture for a new software product. We ask them to tell us a story about a piece of software or infrastructure that they built. All this focus on building things ensures that we’ll end up hiring a candidate who can build things.
And yet, when you work in SRE or operations, or really any backend engineering role with an on-call rotation, troubleshooting is one of your core responsibilities. Some months, you’ll spend far more time troubleshooting than building. So shouldn’t your troubleshooting skills be evaluated during the interview process?
When I talk about interviewing candidates for troubleshooting skills, I mean answering questions like:
- Can they distinguish relevant from irrelevant facts?
- Do they seek to answer specific questions?
- Will they keep an open mind about the cause of a problem, rather than jumping to a conclusion?
- Are they able to express their thought process to a colleague?
- When they hit a dead end, will they get discouraged? Or will they calmly seek out a different approach?
- Do they have a strategy?
Several times throughout my SRE career, I’ve put together interview processes to screen for these skills. The most effective method I’ve found is to create a sort of interactive role-playing game in which the candidate tries to solve a tricky bug in a complex system.
In this post, I’ll show how I went about creating one of these interview questions and how I evaluated the performance of candidates. I hope you’ll be able to copy my approach and produce your own such interview scenario (please reach out if you try this!). If you do, you’ll raise the bar for diagnostic skills on your team, and your operations will run that much more smoothly.
The incident
Around a year into my stint at $lastJob, I was tapped to organize an ongoing investigation into weird, customer-facing, nondeterministic-seeming API timeouts.
The API in question was essentially a private software package registry. But the authentication logic that made the registry private was not implemented in the registry itself. Instead, calls to this registry were proxied by a broader, public-facing API, which handled auth/auth considerations. Here’s a diagram of the whole situation:

Timeouts would occur seemingly at random, at a rate of about 1 timeout per 10,000 requests. The content of the request didn’t matter: any given request for the private registry might hang for 10 seconds and then fail. But if you immediately retried the same request, it would succeed.
I led a team of 4 engineers in a diagnostic effort, and after almost 3 weeks of methodical investigation, we finally got to the bottom of these timeouts. Along the way, we stumbled into several dead-ends and chased a fair number of red herrings.
I’ll spare you most of the details, but it’s important to note the existence of all these dead-ends. They later served as a signal that this problem was sufficiently complex and counterintuitive to give interview candidates a real workout. When you go searching for an incident to turn into a troubleshooting skills interview, look for investigations with lots of dead-ends.
Anyway, the root cause (come at me) ended up being as follows. When requests arrive at the private registry, they’re served by one of N identical “backend” processes (in the diagrams below, N=3). A server distributes requests to these backends, always picking an idle backend if one exists:

If no backend is idle, then the server must queue up the incoming request behind an in-flight request:

What we found is that, occasionally, a particular script would execute an extremely long-running request against the registry API. This would normally be okay, but once in a blue moon, a few of these long-running requests would happen to hit the same server. This tied up multiple backends, resulting in one or more requests (☆) getting queued behind these pathologically long-running requests (△):
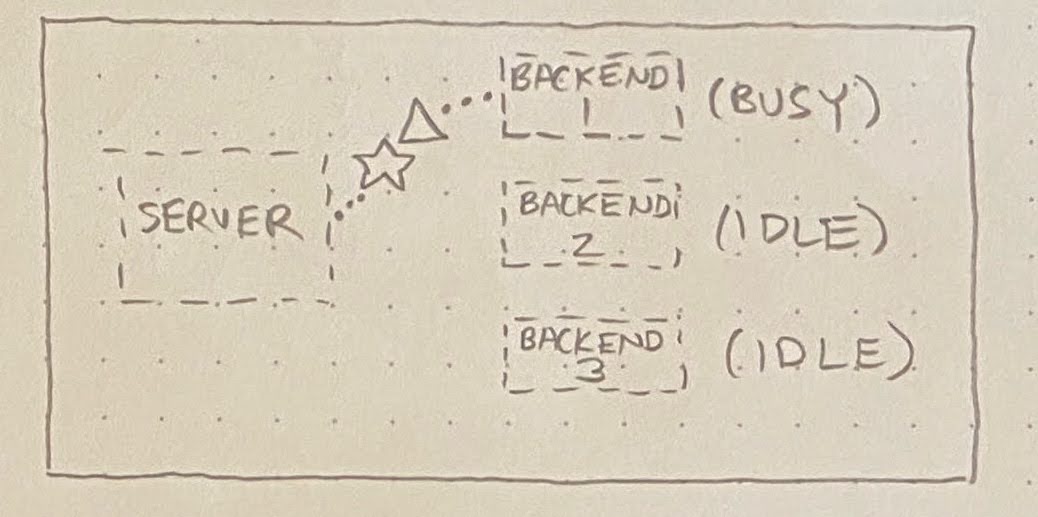
Altogether, this made for a very confusing set of observations:
- Requests passing through the fronting API would occasionally take extra long, regardless of their content.
- If one of these requests took longer than 10 seconds, a timeout would be reached in the CLI, resulting in a customer-facing error message. In this situation,
- The request would continue running in the fronting API, and would be logged by that system as a high-latency 200.
- This same request would be logged as a low-latency 200 at the registry level, since that subsystem would not start its stopwatch until the backend started processing the request.
- At the load balancer, this request would be logged as a 499, which means “the client closed its connection before we could send a response.”
- If one of these requests took longer than 60 seconds, though, a load balancer timeout would be reached.
- The fronting API would log a 499
- The load balancer would log a 502 Bad Gateway
- The registry would never log this request at all.
The confusing nature of these symptoms is what made this issue such a perfect model for our troubleshooting interview.
How I turned this into an interview question
A while after this confusing incident was resolved, I was faced with the prospect of hiring SREs for my team. Since I’m very much a “squeeze the problems out of the system you have” person, rather than a “build new stuff with less problems” person, I wanted to make sure our interview process screened for good diagnostic skills.
So I reviewed the registry timeouts incident. How could I turn that messy, roundabout, real-world investigation into an approachable interview question that would help me gauge a candidate’s troubleshooting skills?
I changed some names, removed a couple complicating factors that would just muddy the waters, and wrote up a training document for interviewers. The training document included:
- A description of the hypothetical architecture in which the exercise would take place;
- A detailed explanation of the issue to be investigated, including discussion of the implications this issue would carry for observable artifacts (e.g. metrics, logs, traces, error messages);
- A guide to conducting the interview (what to say, what not to say, how to evaluate responses).
The document’s description of our hypothetical architecture included a bird’s-eye-view diagram of our made-up architecture:

A service called “Vasa” took the place of the fronting API described earlier. Postgres was included in the diagram despite its irrelevance, introducing a bit of misdirection.
To stand in for the private registry where all the queueing nonsense happened, I made up a microservice called “Argos.” It’s not shown in the bird’s-eye-view diagram. Instead, once the candidate localized the problem to the Argos service, I’d show them another, more zoomed-in diagram that included details of the Argos architecture.
One key modification was that I made Argos (the private registry stand-in) into a generic “workspace metadata storage service.” I didn’t want candidates to fixate on the software-registry aspect of the problem, since that wasn’t especially relevant. People understand metadata storage and retrieval, and it’s boring, so they don’t ask many questions about it.
Conducting the interview
The actual interview takes the form of a role-playing game, almost D&D-esque. I start with a brief spiel:
This is going to be a sort of troubleshooting roleplay adventure, in which you play as an SRE investigating a system problem. I'll lay out the system and the problem under investigation, and you'll get to ask questions and take actions as you see fit. As you learn new things, we can take notes in the Google Doc which I'm sharing now. Sound good? Shall we get started?
After a bit of experience, I added another section to the intro:
The exercise we're going to do is based on a real-world bug that took a team of 4 people several weeks to figure out. I mention this because I don't want you to get to the end of the interview and think, "Oh no! I didn't solve the problem! I must have failed the interview." It's very common for candidates to run out of time without finding the answer but still do very well. I'm much more interested in how you go about investigating the problem than in how far you get.
With that, I show them the architecture diagram (above) and give a bird’s-eye-view description of the system they now “own.” Then we get into the problem:
One day, you get assigned a ticket. According to the ticket, the support team has been getting an increasing number of reports of an issue in which a customer runs a "Get Workspace" command in the CLI, and the CLI hangs for 10 seconds before printing this message and crashing:
ERROR: timeout waiting for response from serverSeveral users have additionally reported that, if they immediately re-run their "Get Workspace" command, it succeeds as normal in under 200 milliseconds.
“Alright,” I say to the candidate, “so you’re assigned this ticket. What do you do first?”
From here, different candidates go in all sorts of different directions. Some want to ask more questions of the support team. Some want further clarity on the architecture. Some immediately dive into logs and metrics. I don’t try to guide them. I just make up plausible answers to their questions, given my knowledge of the underlying problem. For example:
CANDIDATE: Can I ask the support team if there was anything else in common between the customer reports that they received?
ME: Sure. Support doesn't understand quite what you're asking, but they give you links to all the relevant tickets. What do you look for?
CANDIDATE: Are all the tickets from the same part of the world, or all from the same time of day or something?
ME: You don't see any common geographic characteristics. Some of the customers are from North America, some are from Asia, some are from Australia. It does seem, from your limited sample, that most of the reports are from North American business hours, roughly mid-day, on weekdays.
Even this early in the interview, I can sometimes detect warning signs. If a candidate immediately jumps to a specific hypothesis and gets stuck on it, I’m pretty sure this interview isn’t going to go well. But I’ll let them keep going:
CANDIDATE: This sounds like a caching issue, because the requests are failing once and then succeeding on the second try. Are there any caches in the system that might be timing out?
ME: There are many caching layers. There are filesystem caches, of course, and there's the buffer cache in the database. Some data items are cached in Memcache, as you can see in the diagram, and then some of the microservices have caching layers of their own.
CANDIDATE: Okay, then I guess I'd look at the health of those caching layers.
ME: Alright. How would you look at their health? What kinds of things would you look for?
CANDIDATE: Like error messages, high CPU usage, that sort of thing.
This candidate is not likely to do well. Instead of asking targeted questions to hone in on the location of the problem, they’ve leapt to a specific kind of problem (probably one they’ve seen recently in their job) based on very little evidence. Moreover, they’re not looking for the right kind of evidence. They’re looking for evidence that would confirm their suspicion, but when they don’t find any, their suspicion still won’t be ruled out. They could spin their wheels like this for the whole hour. But if that’s what they want to do, I’ll let them.
Since the problem under investigation is sporadic (about 1 in every 10,000 requests), any approach that involves looking at aggregate system-health stats will reach a dead-end pretty quickly. Even good candidates may initially set out in the system-health direction, but they’ll quickly recognize the dead-end and incorporate this new information into their reasoning. They’ll adapt and find a new strategy.
One such strategy is to try to find evidence of the failed requests in the system logs. But I make them work for it:
CANDIDATE: I look in the logs to try to find the requests that are timing out.
ME: Okay. Which logs do you look in? We've got logs from the load balancer, logs from the Vasa service, logs from the DB…
CANDIDATE: The ones for the Vasa service.
ME: The Vasa service has both access logs and error logs. Which one do you want to search?
CANDIDATE: Let's look at the access logs for now.
ME: Cool. How do you find the entries you're interested in?
CANDIDATE: Oh. Hmm. Do we have the client IP addresses for any of the timeouts?
ME: You search through the support tickets, but you don't find any client IP addresses.
CANDIDATE: I guess then I would try to find requests for the Get Workspace endpoint that lasted longer than 9.99 seconds.
When a candidate gives me enough information for a log search, I’ll make up some results, being sure to also document the parameters that were included in the search. For example,
Searching in the Vasa access logs for Get Workspace requests that lasted longer than 9.99 seconds in the last 24 hours, you find:
– 1000 total
– 900: response code 200
– 100: response code 503
This is progress, but candidates often get stuck here for a couple reasons. Some get hung up on the request latencies. They’ll look for requests with latencies of exactly 10 seconds (of which there are none), or they’ll look for requests with latencies around 10 seconds (of which there are a few, most of which are unrelated to the problem at hand.) In the real-world investigation, we found that the borked requests as logged by Vasa had latencies ranging all the way up to 60 seconds, but because the request timeout built into the CLI was 10 seconds, the client would only hang for 10 seconds.
Other candidates would get hung up on the response codes. Since customers are experiencing errors, the investigator would assume that the 503 responses in the log search results above are the ones causing the problem. But in reality, it’s the 200s. Due to mismatched timeouts, the stuck requests can linger in Vasa and Argos until well after the client has gone away, ultimately succeeding but without any client to return their 200 result to.
Once a candidate finds a specific request that they suspect represents an instance of the problem, they usually want to look at a trace. In this situation, I simply draw one by hand using the Insert => Drawing command in the Google Doc. Here’s such a drawing:
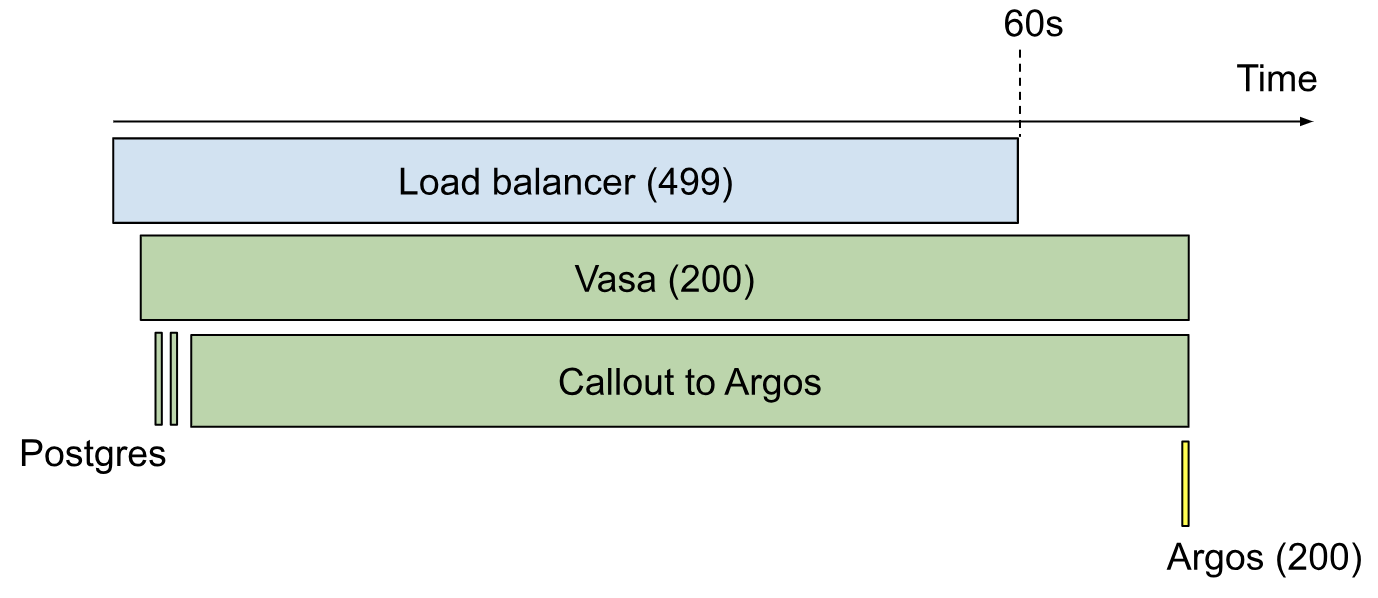
And so the process goes back and forth like this until time runs out. In all the dozens of times I administered this interview, no one ever made it to the end. But, just like I told candidates at the beginning, that’s not what I cared about anyway.
At the end, I ask the candidate to do one last thing:
Alright, you've gotten pretty far, but now let's suppose it's time for you to go home. Maybe you're even going on vacation. How will you update the ticket?
With this prompt, I’m hoping the candidate will describe:
- the relevant new facts they’ve observed,
- the explanations they’ve ruled out, and
- what they recommend doing next.
A candidate who simply lists all the actions they’ve taken and the results of those actions is missing the point. I want to see that they can synthesize their observations into a coherent and succinct form that a colleague with comparable skills will be able to easily pick up where they left off.
Evaluating results
The evaluation of candidates’ performance on this interview goes directly back to the troubleshooting skills that I enumerated at the beginning:
Can they distinguish relevant from irrelevant facts?
If they spent long periods going down rabbit holes that had nothing to do with the timeouts under investigation, then the answer is “no.”
Do they seek to answer specific questions?
When candidates are strong in this area, they’ll reason out loud about their hypotheses. I’ll know why they’re asking for a specific piece of information because they’ll tell me why.
It’s also pretty easy to tell when a candidate is just throwing stuff at the wall to see if anything sticks, and that’s big points off. This is not how you troubleshoot effectively.
Will they keep an open mind about the cause of a problem, rather than jumping to a conclusion?
Often, candidates will fixate on a particular area of the stack. “This really feels like a database problem…” or the like is a common thing to hear. Of course it’s okay – and often good – to have a hunch. But the difference between ineffective and effective troubleshooters is that the ineffective ones will keep trying to prove their hunch right, whereas the effective ones will try to prove it wrong.
Are they able to express their thought process to a colleague?
The “update the ticket” question at the end is very helpful here, but I can usually get solid evidence on this well before then. Throughout the exercise, a good troubleshooter will recognize shifts in their thinking and note them aloud. A not-so-good troubleshooter will leave me in the dark.
When they hit a dead end, will they get discouraged? Or will they calmly seek out a different approach?
On many occasions, I’ve seen candidates get discouraged at a perceived lack of progress. Usually I try to help them find a different direction to go in, and then they’re able to pick their momentum back up. But some people just shut down and stop playing the game. Others go all the way back to the beginning and start casting about for hints in seemingly random parts of the stack. These are signs that the candidate lacks the doggedness required to consistently troubleshoot difficult problems.
Do they have a strategy?
This is what it’s all about. I’m looking to hire someone who makes efficient use of all the resources and information available. Someone who doesn’t just seek out information, but seeks out the particular information that will narrow the search space. It’s only these strategic thinkers who pass this interview, and having subsequently worked with several of them, I can confidently say that this interview technique gets great results.
