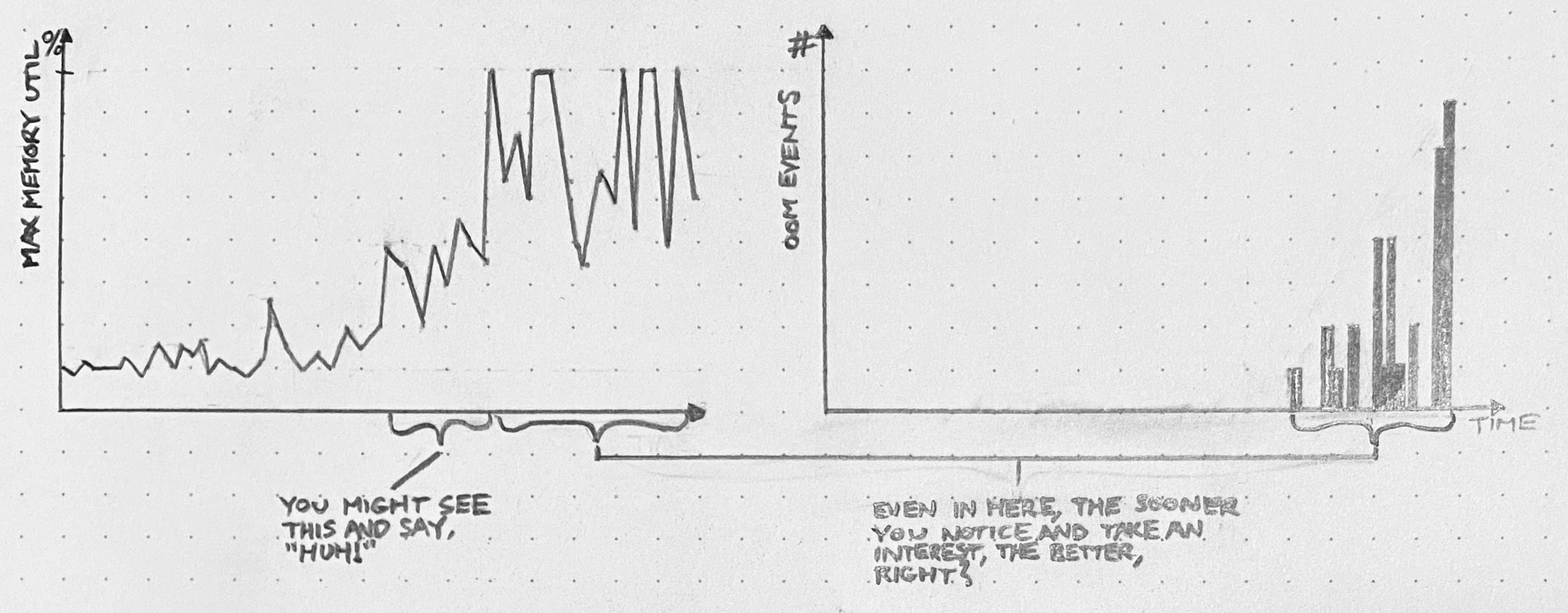
About a year ago, I raised a red flag with colleagues and managers about Postgres performance. Our database was struggling to keep up with the load generated by our monolithic SaaS application. CPU utilization was riding between 60 and 80%, and at least once it spiked to 100%, causing a brief outage.
Now, we had been kicking the can down the road with respect to Postgres capacity for a long time. When the database looked too busy, we’d replace it with a bigger instance and move on. This saved us a lot of time and allowed us to focus on other things, like building features, which was great.
But this time, it wasn’t possible to scale the DB server vertically: we were already on the biggest instance. And we were about to overload that instance.
Lots of schemes were floated. Foremost among them:
- Shard writes. Spin up a cluster of independent databases, and write data to one or the other according to some partitioning strategy.
- Do micro-services. Split up the monolith into multiple interconnected services, each with its own data store that could be scaled on its own terms.
Both of these options are cool! A strong case can be made for either one on its merits. With write sharding, we could potentially increase our capacity by 2 or even 3 orders of magnitude. With micro-services, we’d be free to use “the right tool for the job,” picking data stores optimized to the requirements of each service workload. Either branch of the skill tree would offer exciting options for fault tolerance and operational resilience.
Either way, everyone had to agree: we’d outgrown our old, naïve implementation. Onward and upward! We can do hard things!
In situations like this, presented with a dazzling array of next-generation architecture options that can be built to last us through the decade, it’s easy to forget what our goal was: to get database performance under control.
Complexity costs attention.
Sometimes, leaps in complexity must be made. It’s generally a good problem to have. If enough demand is being placed on your system to render obsolete your existing technology, then even more growth is probably on the horizon! If you can just put in the investment and build the more advanced architecture now, then you’ll be looking at a bright future of unconstrained year-over-year success.
But don’t just consider the implementation cost. The real cost of increased complexity – often the much larger cost – is attention.
If you decide to shard across databases, then not only must you pay the money-, time-, and opportunity cost of building out the new architecture: you must also take the new complexity into account in every subsequent technical decision. Want to shard writes? Fine, but this complicates every future decision about backups, monitoring, migrations, the ORM, and network topology (just to name a few). And don’t get me started on micro-services.
Just think about how massive these costs are. How much feature delivery will have to be delayed or foregone to support the additional architectural complexity?
Always squeeze first
We should always put off significant complexity increases as long as possible.
When complexity leaps are on the table, there’s usually also an opportunity to squeeze some extra juice out of the system you have. By tweaking the workload, tuning performance, or supplementing the system in some way, you may be able to add months or even years of runway. When viable, these options are always preferable to building out a next-gen system.
Let’s return to the example of the overloaded Postgres instance. In that case, what we ended up doing was twofold:
- Two engineers (me and my colleague Ted – but mostly Ted) spent about 3 months working primarily on database performance issues. There was no silver bullet. We used our telemetry to identify heavy queries, dug into the (Rails) codebase to understand where they were coming from, and optimized or eliminated them. We also tuned a lot of Postgres settings.
- Two more engineers cut a path through the codebase to run certain expensive read-only queries on a replica DB. This effort bore fruit around the same time as (1), when we offloaded our single most frequent query (a
SELECTtriggered by polling web clients).
These two efforts together reduced the maximum weekly CPU usage on the database from 90% to 30%.
Now we can sleep at night. We have a huge amount of room to grow, both in terms of CPU headroom and our ability to shed load from the primary. And furthermore, since our work touched many parts of the codebase and demanded collaboration with lots of different devs, we now have a strong distributed knowledge base about the existing system. We’re well positioned to squeeze it even more if need be.
This doesn’t mean complexity is bad
Of course, I’m not saying complexity is bad. It’s necessary. Some day we’ll reach a fundamental limit of our database architecture, and before that day arrives, we’ll need to make a jump in complexity.
But until then, because we squeezed first, we get to keep working with the most boring system possible. This is by far the cheaper and more practical option.