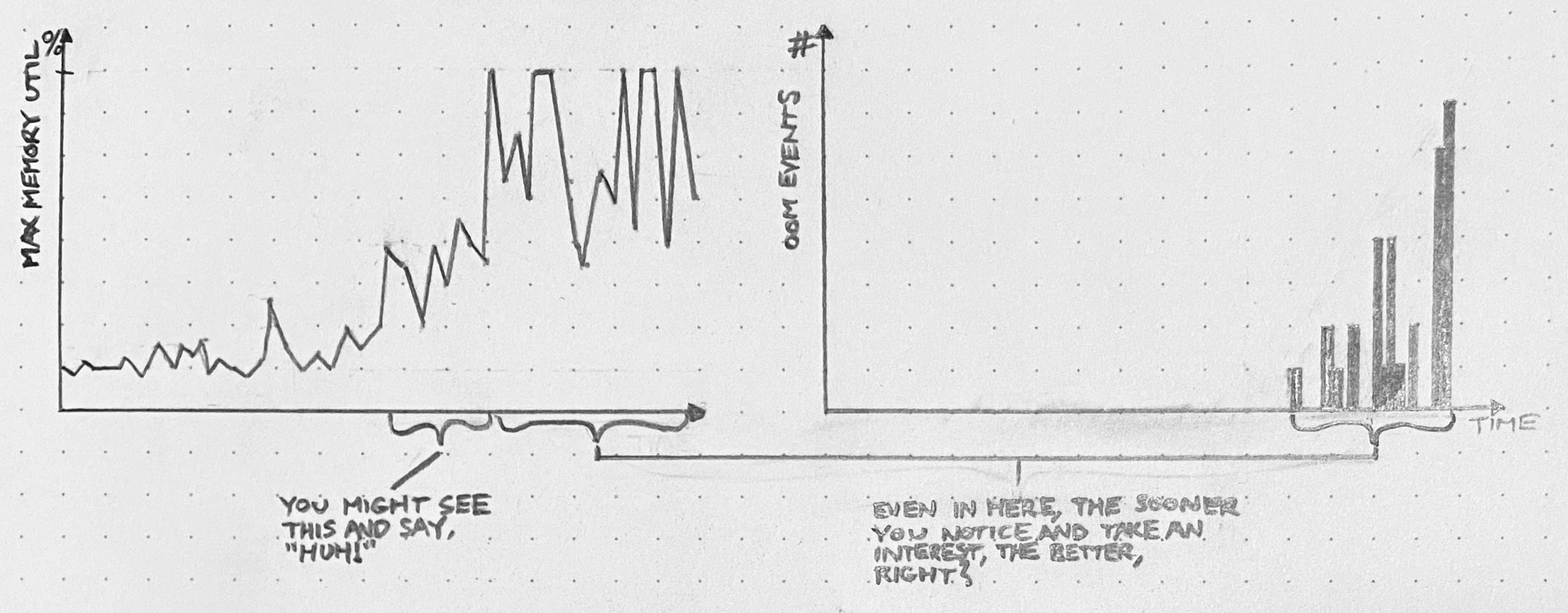
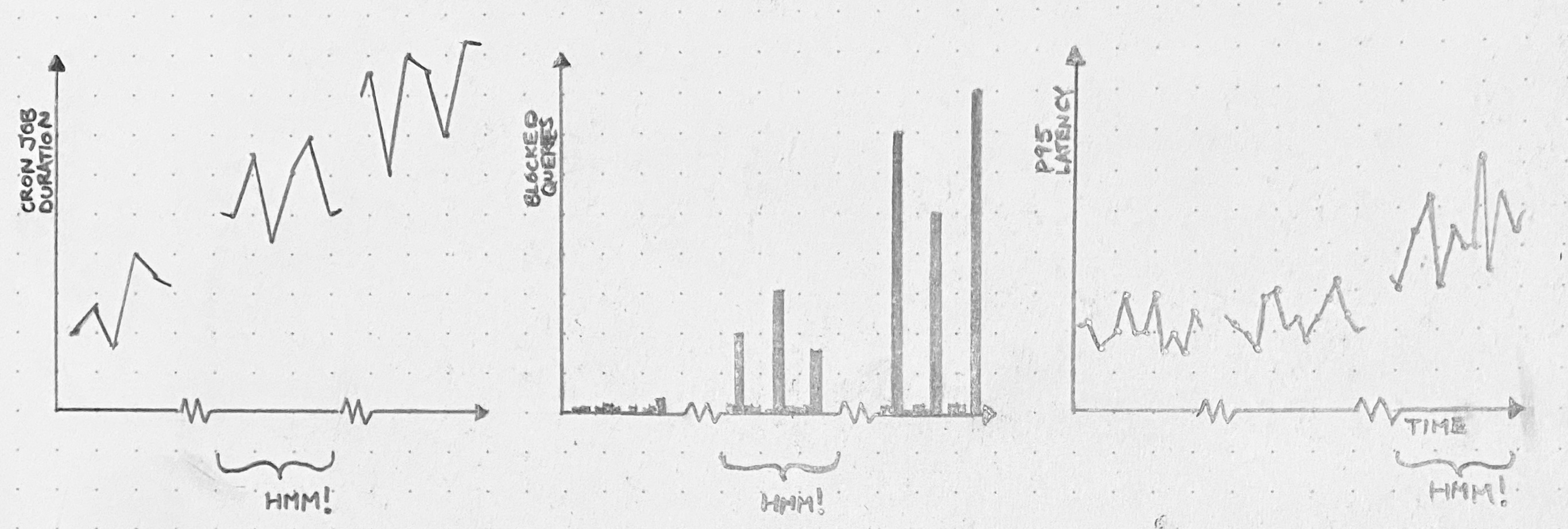
Lately you see a lot of software company R&D teams organized around internal products. The Search Team provides a Search service and its “customers” are the teams whose code consumes that service. The Developer Productivity Team’s product is a suite of tools for managing local development environments and running tests, and its “customers” are the developers who use those tools. And so on.
The idea behind this organizational trick seems to be that product-oriented teams will act like a company. They’ll make better strategic decisions because their goals will be aligned with those of their internal customers.
This is pretty silly.
If a company satisfies the needs of its customers and potential customers, it can grow and thrive and put resources into attracting more revenue. If a company fails to satisfy customer needs, it loses out to competitors. As a company changes its strategy, the market provides feedback. These dynamics don’t exist for an internal team – especially a platform (or “infrastructure,” or “ops”) team.
When asked to think like a company in this way, a platform team will define their product as something like, “a reliable, performant, and secure platform for running software products.” Fine – but think of all the things that a company can do that you can’t do:
- You can’t attract new customers
- You can’t pivot to a different product
- You can’t focus on a different market segment
- You can’t sacrifice some set of customers to attract another
If you try to “think like a company” as a platform team, you will try to do what successful tech companies do: launch attractive features. But you can waste a lot of time that way, because the most important feature of a software platform is boringness.
If the platform team must act like a company, then it should act like a struggling company that’s desperate to keep its last few enterprise customers. This implies a very different strategy than that of a startup. Change as little as possible and put the bulk of your energy into efforts that increase boringness: documenting, simplifying, and fixing. Don’t build anything exciting if you can avoid it, and if you must build something, build it in service of boringness.