Lately you see a lot of software company R&D teams organized around internal products. The Search Team provides a Search service and its “customers” are the teams whose code consumes that service. The Developer Productivity Team’s product is a suite of tools for managing local development environments and running tests, and its “customers” are the developers who use those tools. And so on.
The idea behind this organizational trick seems to be that product-oriented teams will act like a company. They’ll make better strategic decisions because their goals will be aligned with those of their internal customers.
This is pretty silly.
If a company satisfies the needs of its customers and potential customers, it can grow and thrive and put resources into attracting more revenue. If a company fails to satisfy customer needs, it loses out to competitors. As a company changes its strategy, the market provides feedback. These dynamics don’t exist for an internal team – especially a platform (or “infrastructure,” or “ops”) team.
When asked to think like a company in this way, a platform team will define their product as something like, “a reliable, performant, and secure platform for running software products.” Fine – but think of all the things that a company can do that you can’t do:
You can’t attract new customers
You can’t pivot to a different product
You can’t focus on a different market segment
You can’t sacrifice some set of customers to attract another
If you try to “think like a company” as a platform team, you will try to do what successful tech companies do: launch attractive features. But you can waste a lot of time that way, because the most important feature of a software platform is boringness.
If the platform team must act like a company, then it should act like a struggling company that’s desperate to keep its last few enterprise customers. This implies a very different strategy than that of a startup. Change as little as possible and put the bulk of your energy into efforts that increase boringness: documenting, simplifying, and fixing. Don’t build anything exciting if you can avoid it, and if you must build something, build it in service of boringness.
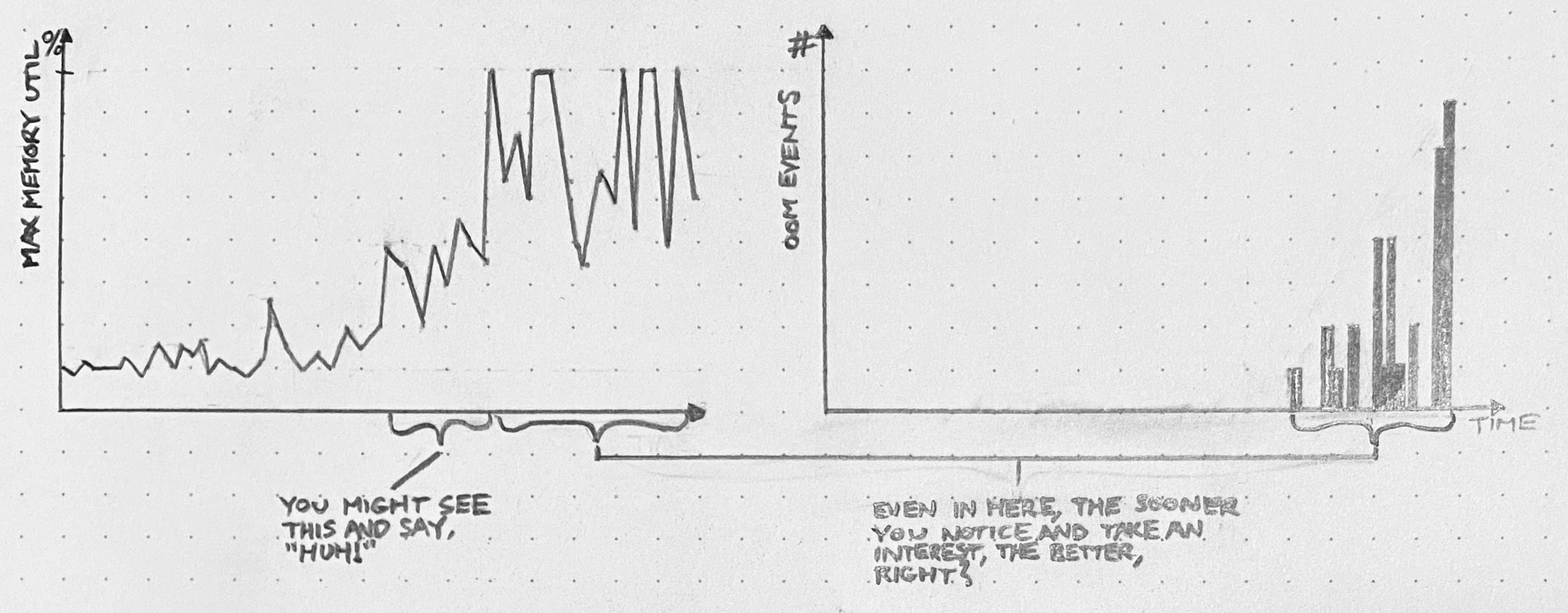
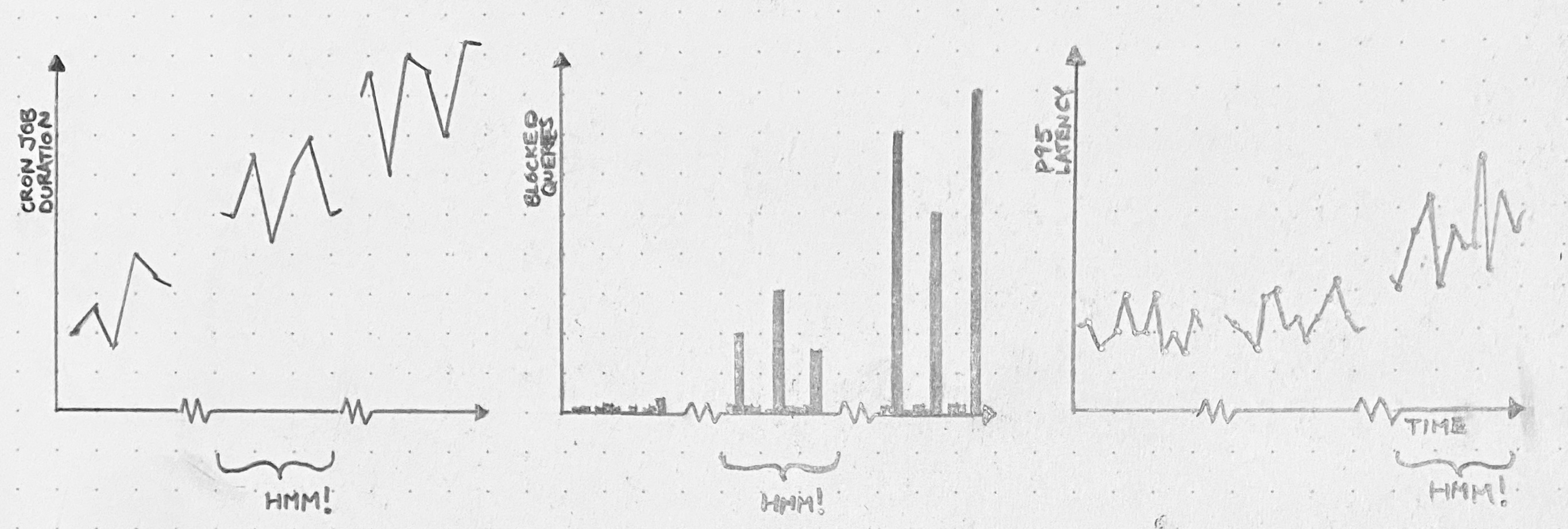
A bug in our deployment system causes O(N²) latency with respect to the number of deploys that have been performed. At first, it’s too minuscule to notice. But the average deploy latency grows over time. Eventually, deploys start randomly timing out. The deploy pipeline grinds to a halt, and it becomes an emergency.
Or maybe, if we think critically about the deploy latency time series soon enough, it might be obvious well in advance that something’s getting worse. We can fix this problem before it becomes a crisis. But in order to see it, we have to look. And we have to give ourselves time to go down the rabbit hole.
An API server has an edge case that leads to unconstrained memory usage. At first, this edge case only gets hit occasionally, and the API server’s memory usage stays well below capacity. But, as usage patterns evolve, we start to hit this bug more frequently, with larger and larger allocations of memory. For a while, we’re still below the OOMkill threshold. Once we start hitting that threshold, things get ugly. If we still continue to ignore it, then eventually, things will get so ugly that we’ll have to drop what we’re doing and fix this bug.
We had opportunities to see this coming. Depending on our willingness to dig in and investigate surprising phenomena, we could have discovered this problem when the OOMkills started, or even before they started – when these blips were just spikes on a memory graph.
A cron job runs every 30 minutes, and while it runs, it holds a database lock. When it’s first deployed, the cron job doesn’t have much to do, so it runs fast, and no one suffers. Over months, though, the cron job grows sluggish. It just has more work to do. Query pileups start to occur every 30 minutes. We start seeing significant impact on the latency of our application. And, one day, there’s an outage.
We’ll wish we’d dug in back when it was just a slow cron job. Or even when it was just query spikes.
You can prevent many things from turning into fires, but you need space. Space to be curious, to investigate, to explain your findings to yourself and others.
Suppose you spent a week looking for trouble like this, and you only happened to find 1 issue out of these 3. That’s still great, right? Compared to the cost of letting it become a disruption later?
When a system fails, it’s silly to blame practitioners for not seeing the signs. But that doesn’t mean we shouldn’t put in a serious effort to see the signs. If you give yourself space to follow the Huh!, you get opportunities to fix problems before they get worse.
Every time our system fails, and we go to analyze the failure, we find ourselves saying things like “We didn’t know X was happening,” “we didn’t know Y could happen,” and so on. And it’s true: we didn’t know those things.
We can never predict with certainty what the next system failure will be. But we can predict, because painful experience has taught us, that some or all of the causes of that failure will be surprising.
We can use that!
When we go looking at data (and by “data” I mostly mean logs, traces, metrics, and so on, but data can be many things), sometimes we see something weird, and we go like, Huh!. That Huh! is a signal. If we follow that Huh! – get to the bottom of it, figure it out, make it not surprising anymore – two things happen. First, we get a chance to correct a latent problem which might some day contribute to a failure. And second, we make our mental model that much better.
Of course, any individual Huh! could turn out to be nothing. Perhaps there’s a bug. Perhaps circumstances have shifted, and our expectations no longer line up with reality. Or perhaps it’s just a monitoring blip. We won’t know until we run it down.
But, whatever the shortcomings of any particular investigation, a habit of investigating surprises has many attractive qualities. The main one is that we get to fix problems before those problems get worse, start bouncing off other problems, and cause fires. In other words: our system runs smoother. Consider what that’s worth.
One day not long ago, as I was looking for trouble in a production system’s telemetry, I came across a puzzling phenomenon. I was examining the load balancer access logs for a particular API endpoint – an endpoint that does essentially nothing and should always return a 200 response within a handful of milliseconds. I saw this:
Metric
Value
My reaction
10th percentile latency
10ms
Okay,
Median latency
11ms
sure,
75th pecentile latency
14ms
fair enough,
90th percentile latency
160ms
mm-h– wait,
99th percentile latency
700ms
What??
“What gives?” I wondered aloud, cocking my head. “What could this request possibly be doing for 700 milliseconds? It has nothing to do.” That’s how I learned about an issue I’m calling upstream-local queueing. It’s a mostly stack-agnostic performance problem, and boy am I glad I found it early, because it has some dire scaling implications.
The problem
I’ll spare you a recapitulation of the head-scratching and data fumbling that ensued. Upstream-local queueing is when an upstream – an individual server tasked with responding to requests – is asked to handle more requests than it can handle concurrently. For example, suppose you have a cluster of load balancers, all of which independently distribute requests to upstreams. Each upstream has a maximum concurrency of 3.
Upstream-local queueing happens when, due to random chance, a particular upstream has 3 requests in flight, and happens to receive a 4th. The upstream can’t immediately start processing that 4th request, so it waits in a queue until some capacity frees up. And in the meantime, maybe a 5th request arrives. And so on.
So, even though the rest of the upstream cluster might have plenty of idle capacity available, these requests end up sitting around twiddling their thumbs, accumulating latency.
You’ll notice that I haven’t mentioned any particular technologies or load balancing algorithms yet. That’s because upstream-local queueing is a remarkably general phenomenon. The following system characteristics are sufficient for this problem to emerge:
The upstreams have finite capacity to handle concurrent requests.
The load balancer’s decisions about where to send each request are independent from each other.
Many systems satisfy these criteria.
It’s hard to observe
Upstream-local queueing can be tricky to observe directly. A queue can appear and disappear on any given upstream within a matter of milliseconds: far shorter than the time scales on which metrics tend to be collected. ULQ’s contribution to request latency therefore appears to be randomly distributed, and mostly 0.
Furthermore, at least in my case, the stack is not instrumented well for this. Upstream-local queueing occurs in somewhat of a black box. It’s an open-source black box, but due to the design of the component that’s handling these requests within the upstream, it’s non-trivial to observe the impact of ULQ.
Further furthermore, the severity of ULQ-caused latency is coupled to utilization, which in most real-world systems is constantly changing. And, furthestmore, unless you’re already in deep trouble, ULQ’s impact tends to be below the noise floor for all but the most painstaking measurement techniques.
The most painstaking measurement techniques
When I first set out to examine the upstream-local queueing phenomenon, I took a highly manual approach:
Pick an upstream
Search for load balancer access logs corresponding to requests that were sent to that upstream
Dump a CSV of those log entries
Run a script against the CSV that uses the timestamps and durations to reconstruct the number of requests in-flight to that upstream from instant to instant.
This was a pain in the ass. But I only had to do it 2 or 3 times before I determined that, yes: this was indeed happening, and it was causing nontrivial latency.
At this point, I was sure that I had found a big problem. But I couldn’t just go fix it. I needed to convince my colleagues. In spite of this problem’s recalcitrance to direct observation, I needed a clear and compelling demonstration.
A computational model
Lucky for me, queueing systems are easy to model!
I spent a day or two building a computational model of the behavior of an upstream under load. The model is on my GitHub. I won’t bore you with the details, but essentially, requests arrive at the upstream at a set interval, and each request takes a random amount of time to execute. If there are more than 12 requests in flight, further requests are queued until slots free up. We add up the number of microseconds spent queued versus in flight, and voilà: a working model that largely agrees with our real-world observations.
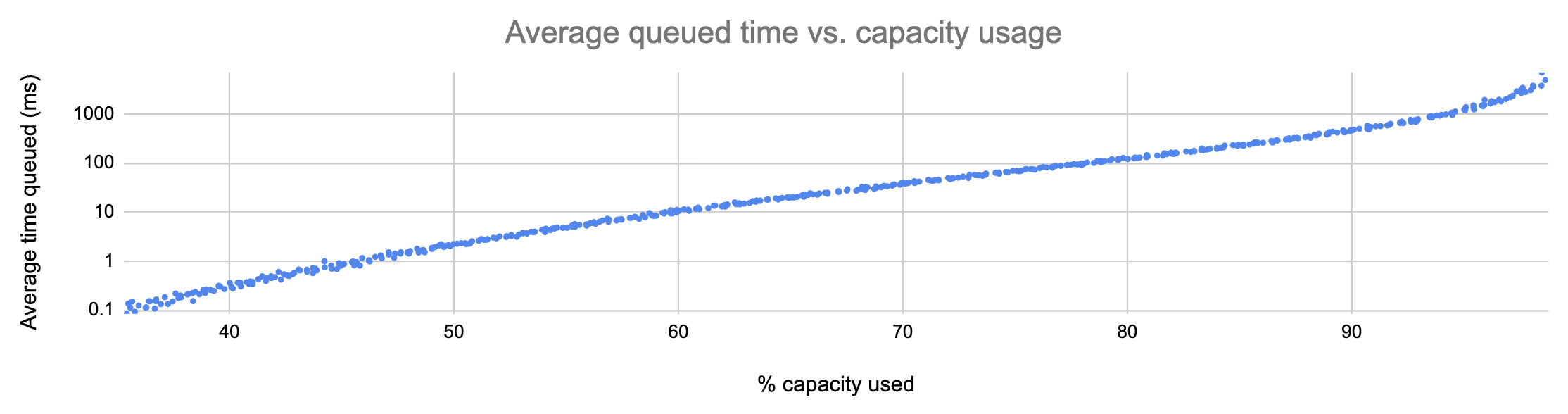
Here’s what the model told me:
In the graph above, each point represents a run of the simulation with a different average request rate. As you can see, the average number of milliseconds spent by requests in the upstream-local queue is tightly correlated to utilization, and it grows more or less exponentially.
This is a huge problem! As more capacity is used, requests experience, on average, exponentially more latency:
% capacity used
Average latency due to ULQ
40%
0.29ms
50%
2.22ms
60%
11.4ms
70%
38.4ms
80%
127ms
90%
461ms
95%
1372ms
And remember: this is just on average. 90th- and 99th-percentile latencies can climb to unacceptable levels far sooner.
What’s worse, ULQ affects all requests equally. If the average added latency is, say, 10ms, then a request that would normally take 1000ms will instead take 1010ms, for a slowdown of 1%. But a request that would normally take 5ms will take on average 15ms: a 300% performance hit. This means more requests sitting around in your stack eating up resources for no good reason. It also means, if clients of your service tend to do many individual requests in sequence (like a web browser, for example), that overall user experience can suffer drastically before this problem even appears that bad.
What to do about it
As I said before, this is a quite general problem. Switching web servers won’t fix it, nor will scaling up. Switching from random-number to round-robin load balancing, or vice versa, will not fix it. There are 3 classes of solution.
The first class of solution is the dumbest. But hey, maybe you need your upstream-local queueing problem fixed now and you don’t have time to be smart. In this case, here’s what you do: set a threshold, and meet it by keeping enough of your capacity idle. Referring to the table above, if we decided on a threshold of 11ms average ULQ latency, then we’d need to keep at least 40% of our capacity idle at all times.
I told you it was dumb. But it is easy. The other two solutions are less easy.
The second solution is to reduce your application’s latency variance. If some requests take 10 milliseconds and others take 30000, then upstream-local queueing rears its ugly head. If, instead, all your requests take between 30 and 35 milliseconds (or between 3 and 3.5 seconds, for that matter), its effect is much less pronounced. By hacking away at the long tail of your latency distribution, you may be able to push the worst effects of ULQ further to the right-hand-side of the graph. But, at the end of the day, exponential growth is exponential growth. It’s not really a fix.
The best thing you can do, of course, is use a more sophisticated load balancing algorithm. This necessitates that your load balancing software supports one. If, for example, you use a least outstanding requests algorithm, then upstream-local queueing simply won’t occur until you’ve exhausted all of your upstream capacity. It ceases to be a scaling problem.
How to tell how bad ULQ is in your stack
For a quick and dirty answer to the question “How much latency is ULQ contributing in my system?” you can make a simple graph dashboard. Take the 90th percentile latency as measured by the load balancer, and subtract the 90th percentile latency as measured by the upstream.
If these curves grow and shrink along with your throughput, you probably have an upstream-local queueing problem. And if the peaks are getting higher, that problem is getting worse.
The numbers resulting from this calculation are not a rigorous measurement of anything in particular. You can’t really add or subtract percentiles. But it’s often a very easy calculation to do, and as long as you don’t make inferences based on the values of the numbers – just the shapes of the curves – you can get some quick confidence this way before you proceed with a deeper investigation. And then you can fix it.
I just finished reading Seeing Like A State: How Certain Schemes to Improve the Human Condition Have Failed by James C. Scott (full text online). I highly recommend it. Through examples ranging from Soviet collectivization to the construction of Brasilia, the book argues that grand, centralized planning efforts in the high modernist tradition are all doomed to failure. One simply can’t substitute pure reason – no matter how beautiful and internally consistent – for local human decision-making informed by direct experience.
To take one striking anecdote, Le Corbusier spent some time lobbying Soviet intelligentsia to implement his redesign of Moscow. However:
Stalin’s commissars found his plans for Moscow as well as his project for the Palace of Soviets too radical. The Soviet modernist El Lissitzky attacked Le Corbusier’s Moscow as a “city of nowhere, … [a city] that is neither capitalist, nor proletarian, nor socialist, … a city on paper, extraneous to living nature, located in a desert through which not even a river must be allowed to pass (since a curve would contradict the style).” As if to confirm El Lissitzky’s charge that he had designed a “city of nowhere,” Le Corbusier recycled his design virtually intact—aside from removing all references to Moscow—and presented it as La ville radieuse, suitable for central Paris.
Seeing Like A State – James C. Scott
In Scott’s book, this pattern plays out over and over. Planners, relying heavily on what they imagine are universal principles, produce designs for human life that are nevertheless completely at odds with how humans actually live and work. These designed spaces possess a symmetric, holistic beauty which blinds their creators to the needs of the infinitely complex human communities that are meant to populate them. The planned city ultimately fails to improve the human condition, since improving the human condition is one of the many considerations which must bow to the planner’s aesthetic.
Toward the end of the book – although this is only a short passage and certainly not the thrust – Scott gives 4 rules of thumb for development planning. Building up a SaaS product is clearly different in many ways (not least of which is the stakes) from planning human development. But the parallels got me thinking in engineering terms, and I find that these rules also work quite well as rules of thumb for making changes to a complex software system. By following them, we can mostly avoid wasting effort on huge endeavors that end up being Cities of Nowhere.
1. Take small steps
In an experimental approach to social change, presume that we cannot know the consequences of our interventions in advance. Given this postulate of ignorance, prefer wherever possible to take a small step, stand back, observe, and then plan the next small move.
In software, taking small steps is a challenge of discipline. We work with pure thought-stuff. In principle, we can build whatever we can imagine, so it’s always tempting to solve more of the problem.
But taking small steps has by now become the common wisdom in our industry. Single-feature pull requests are encouraged over massive, multifaceted ones. We roll out features to small groups of users before ramping up. Prototypes and MVPs abound.
Where we still have much to learn from Scott is the “stand back, observe” part. Often, we’re tempted to simply let the machine do the observing for us: if there’s anything wrong with our change, the integration tests will fail, or the deploy will fail, or we’ll get an alert. While such automated signals are indispensable, they’re not sufficient. To understand the real-world effects of our small changes, we have to exercise the further discipline of curiosity. With our particular change in mind, we have to search diligently for evidence of its effects, both intended and unintended, direct and indirect. Observability is not enough – we must actively observe.
2. Favor reversibility
Prefer interventions that can easily be undone if they turn out to be mistakes. Irreversible interventions have irreversible consequences. Interventions into ecosystems require particular care in this respect, given our great ignorance about how they interact. Aldo Leopold captured the spirit of caution required: “The first rule of intelligent tinkering is to keep all the parts.”
It’s pretty clear how this reversibility consideration applies to deploying software and infrastructure. Most changes should be trivially reversible by “rolling back” the deploy. Where this is impossible (such as in certain classes of database migrations and infrastructure changes), we come up with more case-specific back-out plans, or we end up inventing reversible patterns despite ourselves. This amounts to an implicit recognition that our changes can always have unexpected consequences. Which is good!
But, in a socio-technical system, the technology isn’t the only thing that gets altered over time. We must also favor reversibility with respect to the social elements – with respect to procedures, policies, and organizational structures.
One pattern I like for this is an experiment ledger. As a team, you keep a running register (e.g. in a spreadsheet) of the different experiments you’re trying. These can be anything from a new recurring meeting to a new on-call rotation to a rearrangement of your kanban columns. Each experiment in the ledger has one or more check-in dates, when the team will discuss the results of the experiment and decide whether to keep going or abandon the course.
Of course, for many reasons, not every change can be reversible. Not least because even after you reverse something, the taste stays in people’s mouths. But taken together with the rest of Scott’s advice, reversibility is a sensible attribute to strive for.
3. Plan on surprises
Choose plans that allow the largest accommodation to the unforeseen. In agricultural schemes this may mean choosing and preparing land so that it can grow any of several crops. In planning housing, it would mean “designing in” flexibility for accommodating changes in family structures or living styles. In a factory it may mean selecting a location, layout, or piece of machinery that allows for new processes, materials, or product lines down the road.
No matter how much time and sweat you put into the design of a system – no matter how much of the problem you try to solve a priori – there will always be surprises. It’s just the nature of a complex system, and even more so for a system with inputs you can’t control (e.g. customer traffic patterns).
Therefore, watch carefully for both expected andunexpected results. That’s what “plan on surprises” means to me: make small, reversible changes, and in the meantime look closely for new unexpected behaviors that you can investigate and understand. This will give you much more insight into your system’s abilities and constraints than any application of pure thought.
4. Plan on human inventiveness
Always plan under the assumption that those who become involved in the project later will have or will develop the experience and insight to improve on the design.
Write with clarity and humility on the motivations for your designs. Explain what you did and what you chose not to do, and why. The reasons for a particular design are never self-evident, no matter what cosmic beauty they may have in your head.
Taken together, Scott’s rules sketch out a pragmatic philosophy for managing the evolution of complex systems. In favor of grand redesigns that attempt to solve all problems at once, one should prefer targeted, reversible changes. We should change significant things about the system only we can fully explain why it’s necessary, and afterward we should exercise diligence and curiosity in making sure we understand what we changed.
In an organization that delivers a software service, almost all R&D time goes toward building stuff. We figure out what the customer needs, we decide how to represent their need as software, and we proceed to build that software. After we repeat this cycle enough times, we find that we’ve accidentally ended up with a complex system.
Inevitably, by virtue of its complexity, the system exhibits behaviors that we didn’t design. These behaviors are surprises, or – often – problems. Slowdowns, race conditions, crashes, and so on. Things that we, as the designers, didn’t anticipate, either because we failed to consider the full range of potential interactions between system components, or because the system was exposed to novel and unpredictable inputs (i.e. traffic patterns). Surprises emerge continuously, and most couldn’t have been predicted a priori from knowledge of the system’s design.
R&D teams, therefore, must practice 2 distinct flavors of engineering. Prescriptive engineering is when you say, “What are we going to build, and how?”, and then you execute your plan. Teams with strong prescriptive engineering capabilities can deliver high-quality features fast. And that is, of course, indispensable.
But prescriptive engineering is not enough. As surprises emerge, we need to spot them, understand them, and explain them. We need to practice descriptive engineering.
Descriptive engineering is usually an afterthought
Most engineers rarely engage with production surprises.
We’re called upon to exercise descriptive engineering only in the wake of a catastrophe or a near-catastrophe. Catastrophic events bring attention to the ways in which our expectations about the system’s behavior have fallen short. We’re asked to figure out what went wrong and make sure it doesn’t happen again. And, when that’s done, to put the issue behind us so we can get back to the real work.
In fact, descriptive engineering outside the context of a catastrophe is unheard of most places. Management tends to see all descriptive engineering as rework: a waste of time that could have been avoided had we just designed our system with more forethought in the first place.
The complexity of these systems makes it impossible for them to run without multiple flaws being present. Because these [flaws] are individually insufficient to cause failure they are regarded as minor factors during operations. … The failures change constantly because of changing technology, work organization, and efforts to eradicate failures.
A complex system’s problems are constantly shifting, recombining, and popping into and out of existence. Therefore, descriptive engineering – far from rework – is a fundamental necessity. Over time, the behavior of the system diverges more and more from our expectations. Descriptive engineering is how we bring our expectations back in line with reality.
In other words: our understanding of a complex system is subject to constant entropic decay, and descriptive engineering closes an anti-entropy feedback loop.
Where descriptive engineering lives
Descriptive engineering is the anti-entropy that keeps our shared mental model of the system from diverging too far from reality. As such, no organization would get very far without exercising some form of it.
But, since descriptive engineering effort is so often perceived as waste, it rarely develops a nucleus. Instead, it arises in a panic, proceeds in a hurry, and gets abandoned half-done. It comes in many forms, including:
handling support tickets
incident response
debugging a broken deploy
performance analysis
In sum: the contexts in which we do descriptive engineering tend to be those in which something is broken and needs to be fixed. The understanding is subservient to the fix, and once the fix is deployed, there’s no longer a need for descriptive engineering.
Moreover, since descriptive engineering usually calls for knowledge of the moment-to-moment interactions between subsystems in production, and between the overall system and the outside world, this work has a habit of being siphoned away from developers toward operators. This siphoning effect is self-reinforcing: the team that most often practices descriptive engineering will become the team with the most skill at it, so they’ll get assigned more of it.
This is a shame. By adopting the attitude that descriptive engineering need only occur in response to catastrophe, we deny ourselves opportunities to address surprises before they blow up. We’re stuck waiting for random, high-profile failures to shock us into action.
What else can we do?
Instead of doing descriptive engineering only in response to failures, we must make it an everyday practice. To quote Dr. Cook again,
Overt catastrophic failure occurs when small, apparently innocuous failures join to create opportunity for a systemic accident. Each of these small failures is necessary to cause catastrophe but only the combination is sufficient to permit failure. Put another way, there are many more failure opportunities than overt system accidents.
We won’t ever know in advance which of the many small failures latent in the system will align to create an accident. But if we cultivate an active and constant descriptive engineering practice, we can try to make smart bets and fix small problems before they align to cause big problems.
What would a proactive descriptive engineering practice look like, concretely? One can imagine it in many forms:
A dedicated team of SREs.
A permanent cross-functional team composed of engineers familiar with many different parts of the stack.
A cultural expectation that all engineers spend some amount of their time on descriptive engineering and share their results.
A permanent core team of SREs, joined by a rotating crew of other engineers. Incidentally, this describes the experimental team I’m currently leading IRL, which is called Production Engineering.
I have a strong preference for models that distribute descriptive engineering responsibility across many teams. If the raison d’être of descriptive engineering is to maintain parity between our expectations of system behavior and reality, then it makes sense to spread that activity as broadly as possible among the people whose expectations get encoded into the product.
In any case, however we organize the effort, the main activities of descriptive engineering will look much the same. We delve into the data to find surprises. We pick some of these surprises to investigate. We feed the result of our investigations back into development pipeline. And we do this over and over.
It may not always be glamorous, but it sure beats the never-ending breakdown.
I do most of the grocery shopping for my family. Which is, of course, a privilege. But it’s a time-consuming privilege. From the moment I enter the supermarket to the moment I enter the checkout line, it’s about 30 minutes on average. Multiply that by 49 grocery trips a year, and you get 24.5 hours spent in the supermarket annually.
That’s 24 hours hours a year when I’d rather be doing basically anything else. The whole experience of grocery shopping grates on my nerves: jockeying for position with all the other shopping carts, getting the goddamn cleanup robot in my way, listening to the inane patter of the pre-recorded PA messages. It’s miserable.
All considered, I don’t mind doing it. My family needs to eat, and this is part of the cost of eating.
Buuut…
Why does it take me so long?
When I finally reach the end of the slog and look in my cart, I can’t help but think, there’s no way this should’ve taken me 30 minutes. There’s just not that much stuff.
So I started paying close attention to how I spend my time. Ideally, the process would look like this:
Walk to where the milk is
Put milk in the cart
Walk to where the eggs are
Put eggs in the cart
Walk to where the bread is
… and so on.
In reality, though, the process is much more like this:
Look at the list and decide what to get first
Walk in the general direction of that item
Hopefully find the item there, and put it in the cart
Take out my phone and check it off the list
Look at the list again and guess which of the remaining items is closest
Walk in the general direction of that, hoping I’ll see the right overhead sign and not miss the aisle
…
This process involves tremendously more context switching than the ideal. Because of deficiencies in my brain, I can’t remember more than 1 or 2 items at a time, and every context switch entails a risk of forgetting what I was in the middle of doing. Compounding with this problem is that my grocery list isn’t sorted in any particular order. I’m at the mercy of my incomplete knowledge of supermarket geography: if I miss an item because I walked past the aisle it’s in, I have to waste time walking back to that aisle.
This close examination of my time expenditure got me thinking: how much of that 30 minutes could be optimized away?
Better grocery shopping through data
It became clear that, if I wanted to spend less time in the supermarket, my best bet was to calculate the most efficient travel path through the store. Backtracking and searching were huge sources of waste. Instead, I wanted to take a single pass through the store, grabbing everything I needed as I went.
The first solution that popped into my imagination was to write a script that could take my shopping list, compare it to data about the supermarket’s layout, and produce step-by-step instructions. The instructions would look something like this:
Starting from the store entrance,
Go up Aisle 24. Find bread on the right side.
Toward the back, find milk on the left side.
Head to Aisle 14. Find yogurt against the back wall.
Go down Aisle 12. Find coffee on the right side.
…
I implemented this as a simple Go program called grocery-run. This script contains a hard-coded shopping list, store layout, and arrangement of items. The simple routing algorithm traverses the aisles in order, walking down any aisle that contains an item on the shopping list, and checking that item off. It keeps track of which direction I’m walking so as to order the items appropriately and predict which side of the aisle the item will be found on. The output of grocery-run looks like this:
This served decently for a few weeks. Each weekend before going to the supermarket, I would transfer my shopping list from the place where my family keeps it (Trello) into the code. Then I’d run the script and transfer the output to written form in a notebook. I was of course losing time with all these transfers, but my main goal at the time was just to validate the hypothesis that a path-finding algorithm like this could save me time in the long run. If that hypothesis turned out to be correct, then from there I could set my mind to optimizing away much of the overhead of using the script.
At the supermarket, I’d follow the instructions on the paper, noting the locations of any items that weren’t yet in my data set for later entry. This data recording too was a drain on my time, but – I reasoned – one that would disappear as my data set grew over multiple trips.
The initial results were encouraging! Even with the extra time spent noting item locations, I was spending the same amount of shopping time per trip. And I was also learning some important things:
The left/right information wasn’t especially useful. Since I was spending no time mucking with my phone (as I was before, when I would refer to the list on Trello many times over the course of a trip), my eyes were free to scan the shelves on both sides of an aisle.
The front-of-store/back-of-store information wasn’t that useful either. Because I always knew which item was next, I would see the item as I reached it. Then I could use my own judgement about whether to continue walking to the end of the aisle or turn back.
Time spent noting item locations was indeed decreasing: from week to week, the store wasn’t getting rearranged much.
A paper shopping list was far more efficient than using my phone. First of all, I didn’t have to go through the distracting and time-consuming exercise of taking my phone out of my pocket, unlocking it, scanning the list, and putting it back. And moreover: since the order of the paper list was aligned with my path through the supermarket, I didn’t even need to spend time or attention checking things off. Everything before the current item had already been grabbed, and everything after it remained.
The next iteration
This grocery-run script served decently, but it ended up being a stepping stone to an even simpler solution. Since I didn’t need the left/right or front-of-store/back-of-store data, it turned out I could replace my whole script with a spreadsheet. When you can replace a script with a spreadsheet, it’s almost always a win.
Here’s the spreadsheet. It does basically the same thing as the grocery-run script. There’s one sheet for the current shopping list, one for the store layout, and one for the arrangement of items within the store.
This spreadsheet makes use of a feature of Google Sheets that I hadn’t leveraged before: VLOOKUP. This function lets you construct a lookup table in one part of your spreadsheet, which can be referenced from another part. I think of this by analogy to JOINs in SQL:
SELECT shopping_list.item
FROM shopping_list
JOIN store_arrangement ON item
JOIN store_layout ON aisle
ORDER BY store_layout.visit_order;
My workflow with this spreadsheet is more or less the same as before:
Transfer shopping list from Trello to spreadsheet
Sort shopping list sheet by the “visit order” column (this step corresponds roughly to running the grocery-run script)
Transfer the resulting list to paper
The final shopping list looks like this:
The left column represents the aisle, with empty spaces indicating repetition.
Before and after
Before this intervention, my grocery shopping process was circuitous and wasteful.
Now it’s much more streamlined. Much less backtracking, no more futzing with my phone, no more checking items off the list and getting distracted in the meantime.
All told, this saves me about 15 minutes a week of shopping time. Over the course of the year, that’s
(15m) * (49 weeks a year, adjusting for vacation) = 12.25h
I like to think of this as about 1 book: due to this optimization, I get to read about 1 extra book a year, or do something else of equivalent value. Plus, I get to spend 12 hours less each year listening to that insipid Stop & Shop PA loop. I’ll take it!
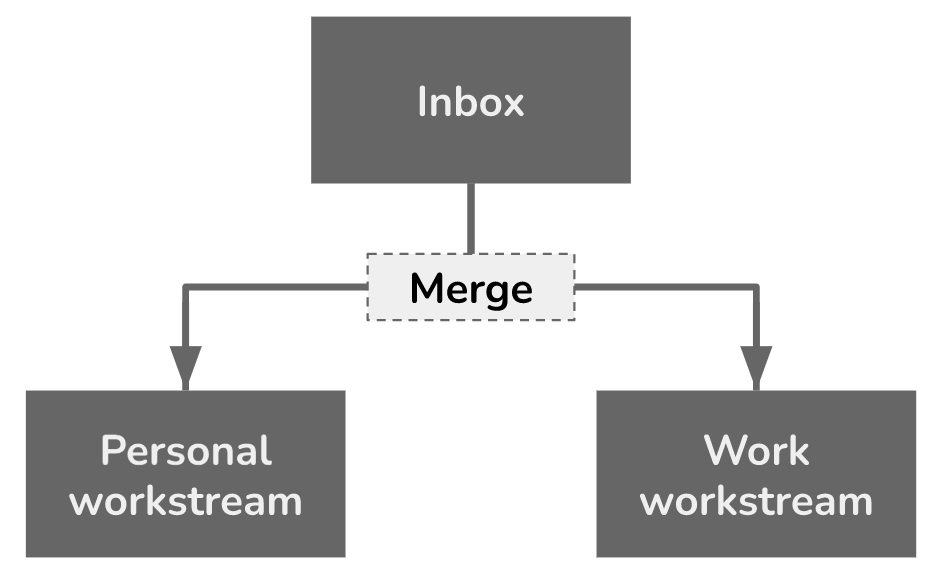
For a year and change, I’ve been using a home-grown, constantly evolving task-tracking system I call Impulse. Part of the deal with Impulse is this: when I think of something I need to get done, I write it down immediately and get back to whatever I was doing.
Later, the thing I wrote down gets merged into a workstream. A workstream is list of tasks in the order I intend to start them. My two main workstreams are work (stuff I’m getting paid for), and personal (stuff I’m not getting paid for).
Impulse’s central principle, which is both obvious and, for me, life-altering, is that the more time you spend doing a thing, the more of that thing you will get done. Sure, there are other variables that play a role in determining output – focus, effectiveness of planning, and a match between your skill set and the work you undertake, to name a few – but time spent working is the most important.
Consequently, I try to arrange my life so as to allot some time every day to working through the tasks in my workstreams. I work from top to bottom, in whatever order the tasks are in at the time I start.
Among the myriad benefits this system has brought to my life is that it mitigates the effect of Ugh Fields.
Ugh Fields
An ugh field is a flinch response to thinking about a given domain of life, conditioned over time through repeated, self-reinforcing negative associations.
For example, I’ve long had an ugh field (or, as I’ve called it before, an attentional sneeze) around replying to texts from my family. I won’t go into how this ugh field developed. It wasn’t my family’s fault; they’re great. Point is, every time I thought about family texts I needed to reply to, my mind would flinch away. Over time, this flinch came earlier and earlier, and with less of a connection to any real source of discomfort. It grew through a feedback loop: think about the texts, flinch away, accrue consequences for ignoring them, think about those consequences, flinch earlier and more forcefully next time.
By succumbing to this ugh field, I’ve done significant damage to my relationship with my family. But the damage is not irreparable, and Impulse is helping me repair it.
Attenuating the ugh field
How can a simple task management system help repair years’ worth of self-conditioning? The key is to decouple the commitment to do a thing from the doing of the thing.
Time was, I didn’t have anywhere in particular to keep track of my plans and obligations. When it occurred to me that something needed doing (e.g. “read that my friend sent me”, “paint the railing on the back steps”, “reply to Dad about getting together in August”), I either had to do the thing right then, or remember to do it later. Thanks to attention deficit, this choice constitutes a dilemma. If I do the thing now, then I’ll lose track of what it was I was doing right beforehand. But if I decide to do the thing later, I’ll almost certainly forget to do it.
Now I have a third choice: record the task in my “inbox.” No matter how trivial it seems, just record it for now and get back to whatever I was doing. Later, on a recurring basis, merge the inbox into my personal and work workstreams.
Right off the bat, this helps. When I think of something I need to do, I don’t need to act on that thought right away. In fact I shouldn’t: that would distract me from whatever I’m already doing. I don’t have to feel bad about putting the thing off, so I don’t have so much of a flinch response.
Then, when it comes time to merge the tasks from my inbox (which is a Google Keep note) into the personal and work workstreams, there’s no longer an ugh field to overcome. I just put each task somewhere on the list, depending on how soon I want to get around to it. Here, another benefit kicks in: I’m forced to compare any new tasks to the other tasks I’ve committed to do, on equal footing.
Work’s just work
Because I’m comparing each task to all the others on a single dimension (i.e. where in the execution order to slot it), instead of a flinch-inducing dreaded obligation, I now just have another piece of work that will take a certain amount of time and create a certain amount of value. Like any other task, there are only 2 ways to get it off the list:
Spend time doing it, or
Decide consciously not to do it.
Either outcome is fine. What matters is that, instead of flinching away from even considering a task, I end up having an explicit conversation with myself about whether and when to do it. This lets me make better decisions.
This benefit is compounded by the way I burn down the workstreams. Somewhere in my day plan, there’s always some scheduled “heads down time,” during which I will execute tasks in a given workstream. For example, starting at 3pm today, I’ll do personal tasks. Always starting from the top of the list.
This means there’s no time to dread the ugh tasks. I don’t have to worry about whether I’m choosing the best thing to work on at a given moment, or what’s next afterward. I just have to trust the commitment I’ve already made to myself and do things in the order I’ve agreed to do them. The deciding is decoupled from the doing, which is an enormous help.
If you’ve come up with a similar arrangement, or if you’ve solved this problem for yourself in a different way, I’d love to hear about it! Hit me up in the comments.
In Technical debt is not a thing, I argue that we should stop using the metaphor of technical debt to inform strategy. Instead, I propose a time horizon model, in which our goal as engineers (or what have you) is to produce the most value possible over some time window.
In the technical debt model, we identify some inefficiency in our workflow process and trace it back to some prior decision that necessitated this inefficiency. That decision, we say, entailed an accumulation of technical debt. We traded away our future productivity for an earlier delivery date. If we want that productivity back, we must “pay off” the debt by rectifying that decision.
In the time horizon model, by contrast, we don’t worry about how we arrived at the existing sociotechnical system. Over the history of the product, we’ve made many decisions to sacrifice completeness for expediency. In making those decisions we went down a path that ultimately led us to the system as it exists today. We can’t go back and choose a different path: there’s only forward.
Let’s say we’ve got a SaaS product that relies on manually generated TLS certificates. We have to do 2 hours of toil every 3 months to renew these certs.
If we believe in technical debt, we might look back at the decision to make cert renewal a manual process and say, “By not automating this, we took on technical debt. We must pay off this debt.” We’d make a ticket, give it the technical-debt tag, and eventually pick it up as part of our 20% time commitment to technical debt paydown.
By contrast, in the time horizon model, our team’s stated raison d’être is simply to produce the most value possible within our agreed-upon time window.
So instead, we’ll say something like “Manual cert renewal costs 2 hours of labor every 3 months. It would take us 15 hours of work to automate.” Those 15 hours could instead be spent delivering value directly, so we should only undertake this project if it will free us up to deliver more total value between now and the time horizon:
Our time horizon
The estimated time investment (which is also the opportunity cost)
The payoff over the time horizon
Our decision
3 months
15 hours
2 hours
Don’t do it
1 year
15 hours
8 hours
Don’t do it
3 years
15 hours
24 hours
Maybe do it
5 years
15 hours
40 hours
Maybe do it
Of course, just because a given time investment passes the time horizon test doesn’t necessarily mean we should make that investment. We still need to compare it to the set of other efforts we could undertake, and devise an overall strategy that maximizes the value we’ll deliver over our time window.
The horizon model gives us a basis for making these comparisons, and lets us establish a lower bound for the expected return on our time investments. It helps us focus on the right things.
In a complex application, there are queues everywhere. Which is lucky, in a way, because it means we can use queueing theory to slice through a whole class of Gordian knots.
One of queueing theory’s most general insights is Little’s Law:
L = λW
L is the long-term average number of customers in the system, λ is the long-term average arrival rate of new customers, and W is the average amount of time that customers spend waiting.
In the parlance of queueing theory, “customer” doesn’t just mean “customer.” It means whatever unit of work needs to pass through the system. A customer can be a phone call or an IP packet or a literal customer at a grocery store or any one of infinitely many other things. As long as there are pieces of work that arrive, get queued, get processed, and then exit the system*, Little’s Law works. It’s breathtakingly general.
As an illustration, let me share an anecdote from my job.
*and as long as you’re not hitting a queue size limit
How many web servers do we need?
I’m on a team that’s responsible for a web app that looks more or less like this:
Requests come in from the Internet to the load balancer. The load balancer forwards the requests to a bunch of web servers, each of which, in turn, distributes requests among 6 independent worker threads. The worker threads run the business logic and send responses back up the stack. Pretty straightforward.
When a web server receives a request, it hands that request off to one of its worker threads. Or, if all the worker threads are busy, the request gets queued in a backlog to be processed once capacity becomes available.
If everything’s hunky dory, the backlog should be empty. There should always be idle capacity, such that requests never have to wait in a queue. But one day I noticed that the backlog wasn’t empty. The total number of backlogged requests across the fleet looked like this:
Things were getting queued at peak traffic, so we needed to scale up the number of web servers. But scale it up to what? I could have used trial and error, but instead, I turned to Little’s Law.
The first step was to establish the mapping between entities in my system and the general mathematical objects related by Little’s Law:
L: the number of in-flight requests. In other words, requests that have arrived at the load balancer and for which responses haven’t yet been sent back to the user.
λ: the rate at which new requests arrive at the load balancer.
W: the average request latency.
What I wanted to know – and didn’t have a metric for – was L. I did have a metric in my telemetry system for W, the average request latency.
While I didn’t exactly have a metric for λ, the arrival rate of requests, I did have the completion rate of requests (i.e. how many requests per second were being served). The long-term average arrival rate can’t differ from the completion rate, since every request does exit the system eventually. Therefore I was able to use the completion rate as a stand-in for λ. Here’s what I found (these aren’t the actual numbers):
I chose an arrival rate close to the peak throughput of the system. This still works as a “long-term average,” though, since the interval between arrivals (on the order of 1 millisecond) is much less than the duration of the average request (on the order of 300 milliseconds).
So, according to Little’s Law, at peak-traffic times, there will be on average 340 requests in flight in the system. Sometimes more, sometimes less, but on average 340. From there, it was trivial to see why requests were getting queued:
(average web server occupancy) = (average occupancy) / (number of web servers) (average web server occupancy) = (340 requests) / (40) (average web server occupancy) = 8.5
If you recall that each web server maintains 6 worker threads, you’ll see the problem. No matter what fancy stuff we try to do with queueing discipline or load balancing algorithm or whatever, there will be on average 2.5 queued requests per worker.
Little’s Law can also tell us what we need to scale up to if we want to extract ourselves from this mire:
(total worker threads) ≥ (arrival rate)(average wait time) (number of web servers)(worker threads per web server) ≥ 340
So we can either scale up web servers or worker threads per web server until their product is greater than 340.
Little’s Law is about long-term averages
This is only a lower bound, of course.
Little’s Law tells us about the long-term average behavior of a queueing system: nothing else. From moment to moment, the occupancy of the system will vary around this average. So, in the example above, we need to provision enough worker capacity to absorb these variations.
How much extra capacity do we need? Little’s Law can’t tell us. The answer will depend on the idiosyncrasies of our system and the traffic that passes through it. Different systems have different latency distributions, different arrival time distributions, different queueing disciplines, and so on. These variables all have some effect on our worst case and our 99th-percentile occupancy. So, in most cases, it’ll be important to get a sense for the empirical ratio between a system’s average occupancy and its occupancy at whatever percentile you decide to care about. But Little’s Law is still a very helpful tool.
If you do have a good sense of how worst-case occupancy varies with the average, you might even be able to use Little’s Law to inform your autoscaling strategy. As long as the system’s arrival rate changes much more gradually than the average latency of requests (such that you’re still working with long-term averages), you can rely on
L = λW
to predict your capacity requirements. Or, at least, I think you could. I haven’t tried it yet.