
If you believe — as I do — that everything worth talking about is measurable, then it probably irritates you sometimes when you hear everybody talk about scalability. We all recognize that we want to build systems that can adapt to changing capacity requirements, sure, but how do you measure how scalable your system is? How do you know when you’ve improved its scalability? How do you know how much you’ve improved it?
I propose that we pick a definition of scalability that lets us attach a number to it. When you say a system is highly scalable what you probably mean is that when you need to add capacity, you can do so without spending too much time or money. So here’s how we should define scalability:
Scalability = d(capacity)/d(money spent)
In case you’re rusty on calculus, this means scalability is the derivative of capacity with respect to money spent. And even if you’re even rustier, think about it as “how much capacity you get for a dollar.”
I’ve got an example that should make it more intuitive.
Calculating the scalability of a web cluster
Suppose you have a cluster of web servers whose capacity you measure in requests per second. A plot of that value over the course of a year might look like this:

Similarly, you could plot the total amount of money (including time spent on labor, if you have to do anything manually), cumulatively spent on web cluster capacity. You probably don’t have this metric, and neither do I (yet), but bear with me.

If you have both of these quantities available, then you can take your capacity datapoints and plot them against money datapoints from the same time. In math, we call this parameterizing by time.

And finally we can get at d(Capacity)/d(Money). For discrete quantities like these, it suffices to plot the ratios between the increments by which capacity and money change. You can easily get at those values with R’s diff() function. Here’s what ours look like:
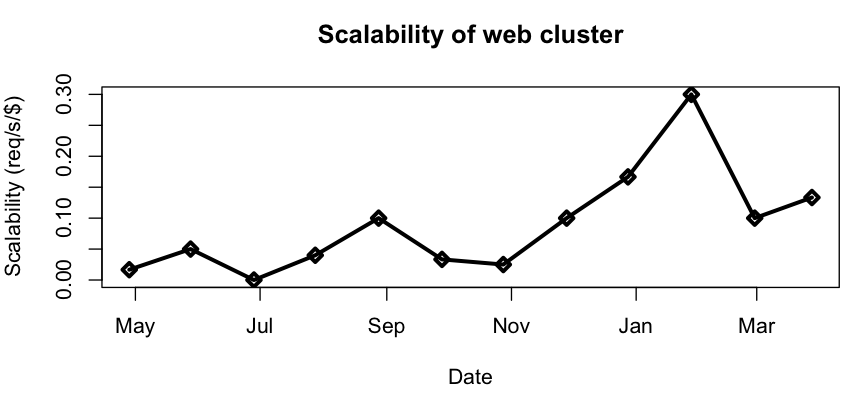
So our scalability has increased since last May. In fact, we can say that it has increased by at least 0.1 req/s/$.
Think about it
I’m sure this is not a super practical calculation for most ops teams. But I do think it’s a useful way to think about scalability. Since I started thinking about scalability in this way, it’s felt more like a real thing. And honestly there’s not that much standing in the way of calculating this number for real, so maybe I’ll start doing it.
What do you think? Do you have a better definition for scalability that yields a quantity?

Neil Gunther’s Universal Scalability Law is a start.
Pingback: SRE Weekly Issue #358 – SRE WEEKLY
Pingback: SRE Weekly Issue #358 – FDE