If you’re a junior engineer at a software company, you might be required to be on call for the systems your team owns. Which means you’ll eventually be called upon to lead an incident response. And since incidents don’t care what your org chart looks like, fate may place you in charge of your seniors; even your boss!

That’s a lot of pressure, and they certainly didn’t teach you how to do it in school. You’re still just learning the ropes, and now they expect you to be in charge? During an outage? And tell more senior engineers what to do? It seems wrong and unfair.
But let your inexperience be an advantage!
Incident lead is not a technical role
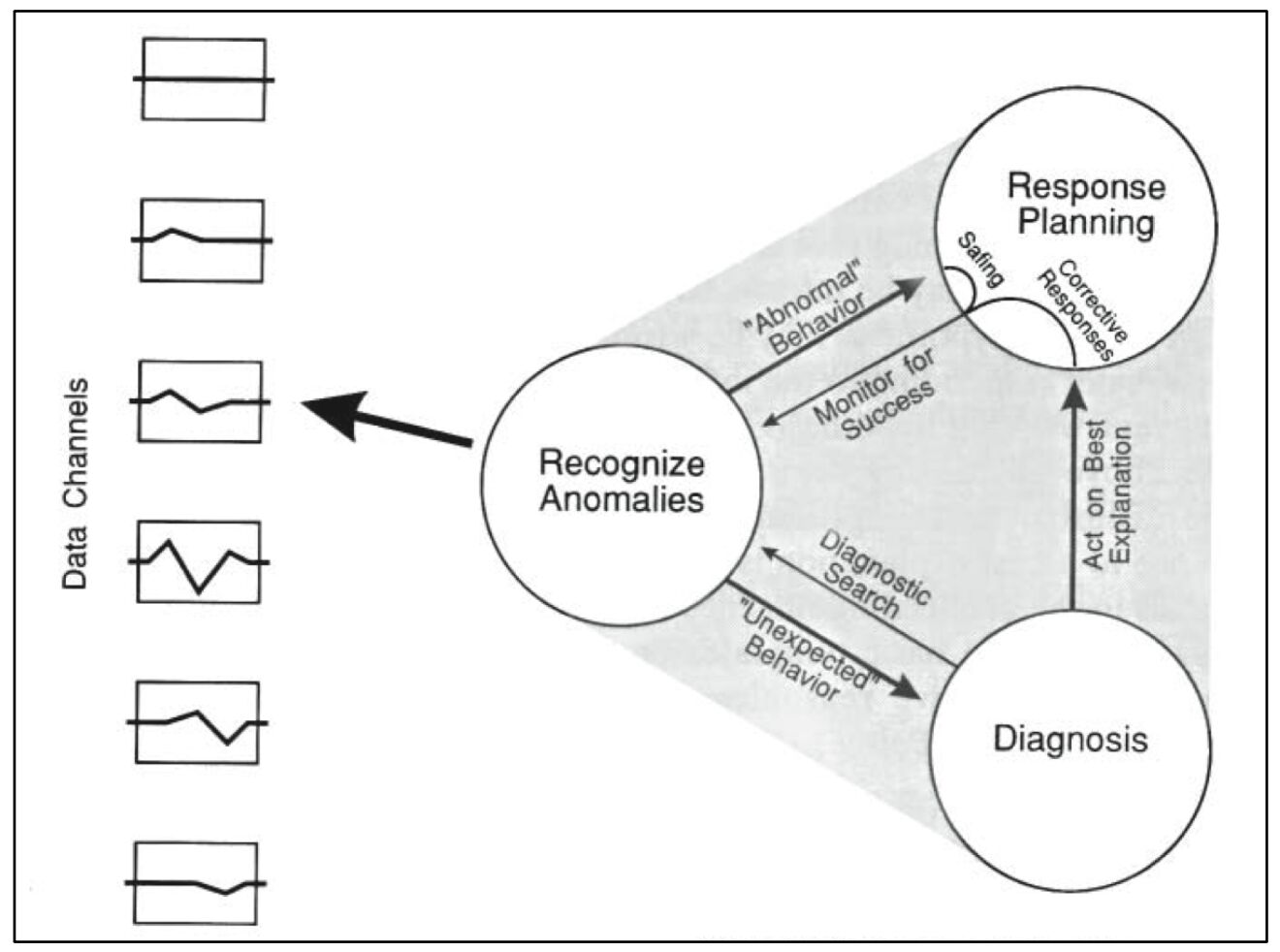
The incident lead is the person accountable for keeping the response effort moving swiftly forward. That involves a wide variety of activities, of which fixing the problem only represents a subset.

Just like the leader of any team, the incident lead’s main job is to keep all the participants on the same page – in other words, to maintain common ground. It’s common ground that allows a group of individuals to work together as more than just individuals. And you don’t need to be deeply versed in the tech to do that. You just need to ask questions.
Aim to understand the problem just enough to make pretty good decisions. Your decisions don’t have to be perfectly optimal. If the primary SME says something like,
It looks like maybe the Chargeover service is borked.
and you don’t know what the Chargeover service is or why it might be borked: speak up! The Primary SME is already deep in the problem space, so they often won’t think to explain what they mean. And chances are you’re not the only one on the call who needs an explanation. As incident lead, it’s up to you to get clarity – not just for yourself, but for the whole group.
As someone who’s new to the tech stack, you’re perfectly placed to ask fundamental questions. So ask. For example, you could ask:
- What makes you say the Chargeover service is borked? Did you see a graph or logs or something?
- I’m not familiar with the Chargeover service – what does it do?
- Do you have a hypothesis yet about why it’s borked?
You won’t need to ask a bunch of questions right in a row. Usually one or two is sufficient to jolt an SME out of “fixing mode” and into “explaining mode.” Then you can draw out enough information to build your own sufficient understanding, and in the process, the whole call will get an improved, shared understanding by listening to your conversation. It will develop common ground.
How do you know when your understanding is sufficient? That’s a job for closed-loop communication. As soon as you think you can, repeat back in your own words the following:
- The symptoms
- The main hypothesis that the SME is entertaining to explain the symptoms
- Any other hypotheses in play
- What action(s) the SME is planning to take
If you say these things and the SME says, “Yup, that’s right,” then congratulations! You’ve successfully established common ground among incident responders. You’ve done a better, more valuable job than the vast majority of incident leads (even ones who are very experienced engineers). Because you asked fundamental questions and listened.
If you’re looking to raise your incident response game, my 3-part course Leading Incidents is just what you need.